5 Different Methods to Scrape Data from Google Trends
![]() Written by James Parsons • Updated April 15, 2026
Written by James Parsons • Updated April 15, 2026


Any time you look up ways to find keyword or topic ideas for content marketing, one of the top options you'll find is Google Trends. Google, positioned as they are on the cusp of all human knowledge, is able to watch the information being posted as it happens and can monitor virtually any topic to see how it changes over time or spikes in sudden interest.
Trend-chasing can be an exceptional way to get a lot of short-term traffic and links. At the same time, it requires a wide breadth of up-to-date information so you know what you're targeting, along with a fast-turnaround content production team to capitalize on those trends as soon as possible.
Unfortunately for those of us in content marketing, Google Trends does not really facilitate this kind of rapid, broad-spectrum monitoring. They have pages for daily and real-time trends on a national level, but there's no way to monitor all of those trends, no way to download or export the bulk data as a CSV, and no way to get repeated, customized data consistently across a wide variety of terms without manually going in and searching each term, downloading each CSV, and compiling all of the data manually.
Needless to say, it's a pretty big hassle.
So, how can you scrape data from Google Trends and use it effectively? You have a few options.
Key Takeaways
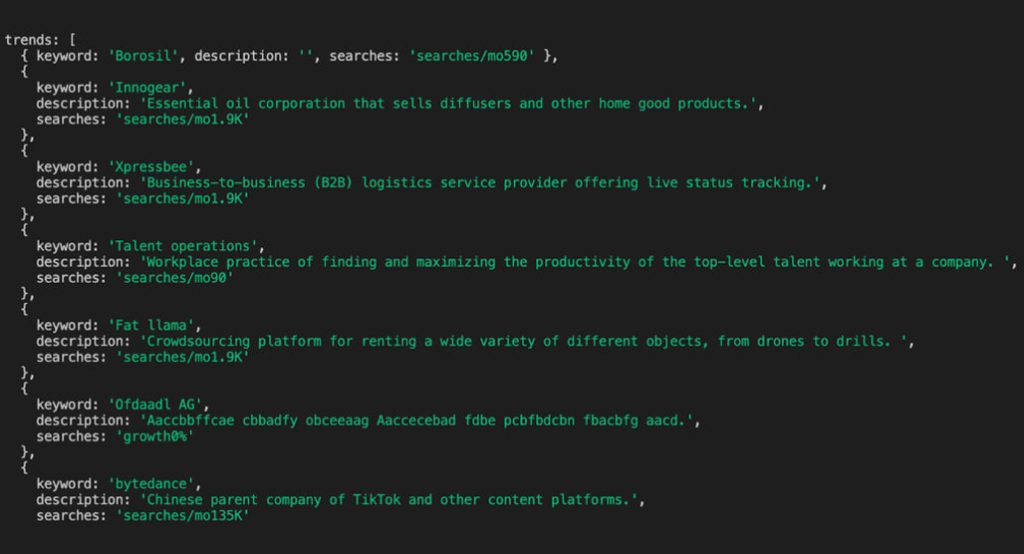
- Google Trends lacks a bulk export or official API, making automated data collection difficult without custom scraping solutions.
- Five scraping methods exist: ChatGPT-generated code, third-party APIs (SerpAPI, DataForSEO), Pytrends library, browser bots, and custom solutions.
- Scraping Google Trends violates their terms of service, though Google has never taken legal action against established tools like Pytrends.
- Rotating residential proxies are essential; headless browsers are easily detected and blocked by Google.
- The article suggests evergreen content outperforms trend-chasing, as trend-driven traffic rarely produces lasting audience growth.
Table of Contents
1: Use ChatGPT to Program a Scraper
AI is a very contentious subject right now. I'm firmly in the "it's not good for content production" camp, but it definitely has its uses. One such use is in coding. Since ChatGPT is built on Python, and since it has scraped pretty much the entirety of sites like GitHub and StackExchange as part of its training model, it's pretty good at something that needs to be specific, accurate, and technical, like programming.
Of course, it's not perfect. ChatGPT doesn't actually have its own dev environment, and it can't do things like "write code that runs" or "guarantee the best possible code."
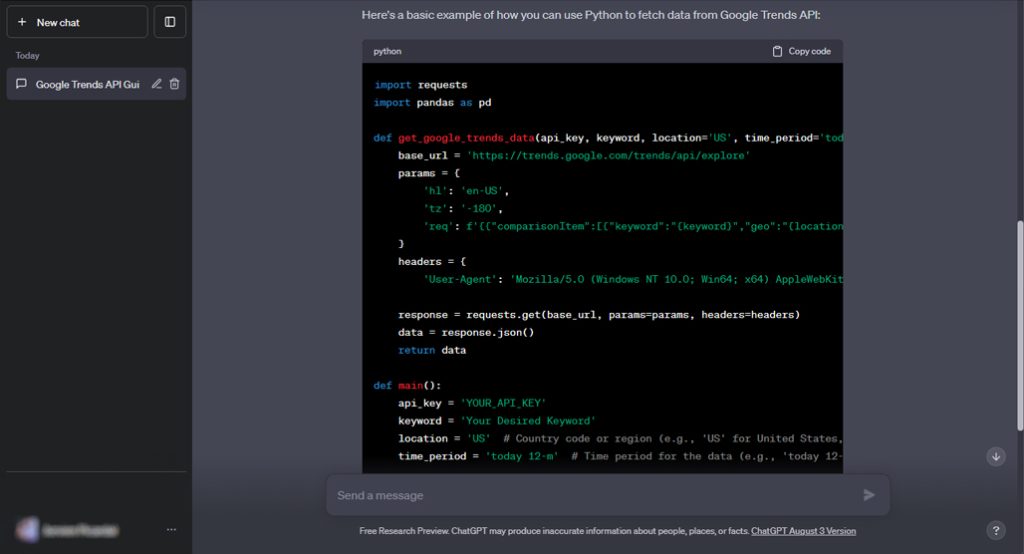
The first example in this post is a good illustration:
"I was quite impressed with the response, especially its suggestion to use gpd.gridify(), a geopandas attribute I've never heard of before. However, when I tried to run the code, I found out that the module geopandas has no attribute gridify. In other words, the chatbot suggested for me to use a tool that looks really handy but doesn't actually exist."
This is called a hallucination in AI terms. Because ChatGPT does not have any way to separate fact from fiction, it can tell you with confidence a fact or a piece of code that isn't real. It's a very interesting and complex problem rooted in the very foundation of how the tool works, but it's also outside of our discussion today, so I'll leave that for another time.
The point is that you can ask ChatGPT to code a scraper for Google Trends, and it will create code for you. You will then need to troubleshoot that code, make sure you understand what it does and where it's coming from, and fix the problems it generates. However, it can do 80% of the drudgery of initial research and coding the framework, which saves you a lot of time and energy. If you're curious about other ways to use this tool, see how ChatGPT can help you build a blog post outline.
2: Use a Third-Party Unofficial API
Google Trends does not offer an official API. If it did, all of this would be a heck of a lot easier. As for why they don't have one, well, there's no official rationale. Some people think it's to protect their proprietary monitoring code; others figure it's a privacy concern. People also speculate that Google just doesn't want to offer something like that for free or that it's on the eventual features list but just so far down that it's never getting made.
That hasn't stopped other people from making their own pseudo-APIs, though.
I call them pseudo-APIs because they aren't truly Google Trends APIs. They're APIs, but they're APIs to a third-party service that uses some other method to scrape Google Trends and simply reformats the data in an API-like format for your use.
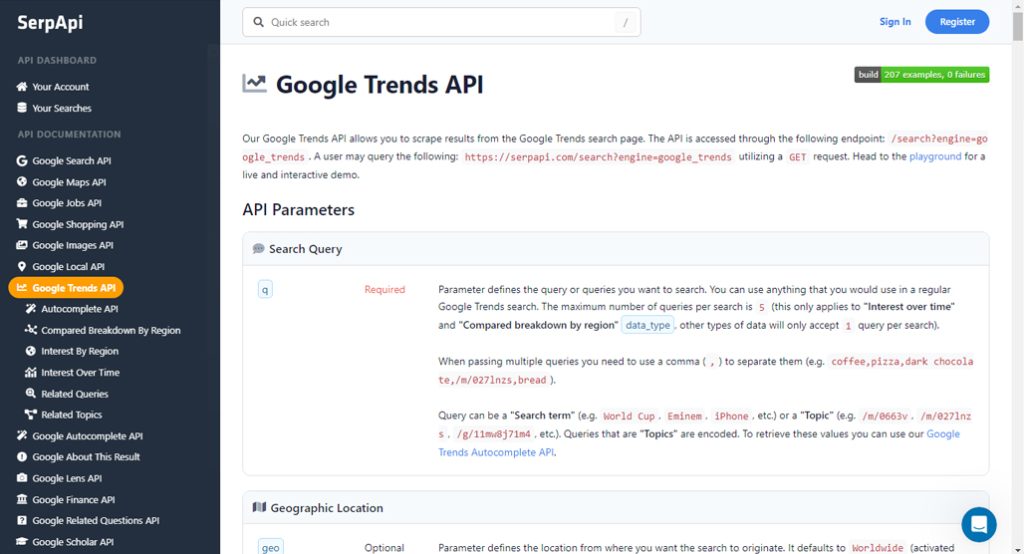
There are a handful of services like this. You can try out SerpAPI, NPM API, or DataForSEO. All of these are basically just interfaces between you and Google Trends, scraping data you request and formatting it so you can get it via API requests. They have varying levels of utility, price points, and other details, so check them out and see what best suits your needs.
3: Use the Pytrends Library
Those of you who already know how to set up a Google Trends API for your own custom code are screaming at me about leaving out one big name from the previous step: Pytrends.
Pytrends is a Python-based Google Trends scraper and API transformer. It's by far the largest, most popular, and best-maintained of the Google Trends API services, and since it's just code up there on the website, you can set up your own instance customized to your needs. Installation is simple, and then it's just a matter of formatting your request to get the data you want, setting up lists of proxies to handle your scraping, and making use of the data.
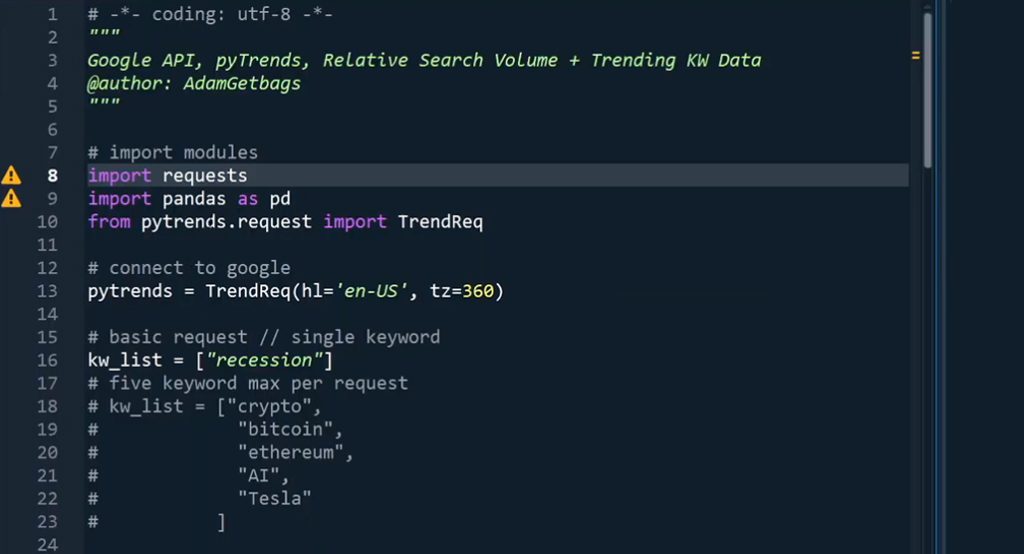
As with other API options, you're beholden to Google's limitations placed on scraping, which means circumventing blocks, adding delays, and generally mimicking human behavior. This can be tricky to set up and may require some trial and error, but I'll go into greater detail on that later on in this post.
4: Use Browser Bots
Do you need an API? Chances are, maybe not. These unofficial APIs scrape data from Google Trends and give it to you in API format, which you then need to translate into something usable, so why not skip the conversion part?
There are a handful of browser-based bots you can use to set up scraping that work just about as effectively as these API scrapers, assuming you've configured them properly.
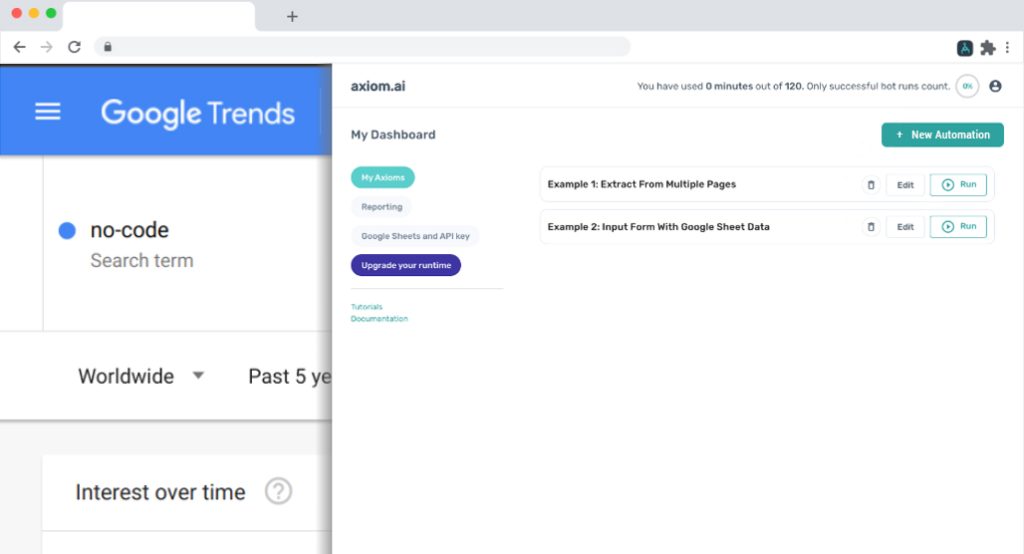
Check out bots like:
Unlike using a Python library or creating your own code, these services generally have fees associated with them. You'll have some amount of data or runtime available for a free trial, but after that runs out, you'll need to pay for ongoing access. Pricing varies, as do the restrictions on various packages, so you just need to look into the options and determine the one that best suits your needs.
I'm more of a "code it yourself" kind of guy, so I don't have personal experience or recommendations with any of these. I'm just presenting them as an option for the people who aren't as immersed in the code sauce as I am. If you're looking for ways to block your own site from scrapers, that's a separate topic worth exploring.
5: Create a Custom Solution
Depending on your needs, the chances are pretty good that none of these options (except maybe ChatGPT) is going to get you precisely what you want. They all either have too much additional cruft, too much data harvesting for your needs (or not enough), or a price point that makes it very much not worth it for you.
So, just make a custom solution.
Whether you use a Python library, some other coding framework, build your own web scraper bot using a drag-and-drop editor or an input recorder, or do something else, there's infinite flexibility in the internet and the way data works.
- Determine your specific needs in terms of data, volume, and format.
- Develop a workflow to get that data and, if necessary, convert it into a usable format.
- Program something to do that process for you and output a file you can use.
- Bing bang boom, you're done!
Okay, so it's never actually that easy. In fact, there are a few significant challenges that I'll talk about momentarily. But, if you need customized, formatted data, nothing beats making the system to get it yourself.
The Challenges of Scraping Google
So, here's the thing. Clearly, there's some demand for Google Trends data in a format outside of the Google Trends interface. But Google doesn't seem keen to provide that data for you and, in fact, throws up roadblocks in your way. There are quite a few challenges you can run into with any of these options.
Is Scraping Google Trends Legal?
Yes and no.
Technically, "automated access" is against Google's terms of use. Using a scraper, bot, or API to access Google Trends (or any other Google page) data is technically a violation of the terms of service. However, even with popular, established platforms like Pytrends, Google has never taken action to take down the code or sue the people responsible for making it.
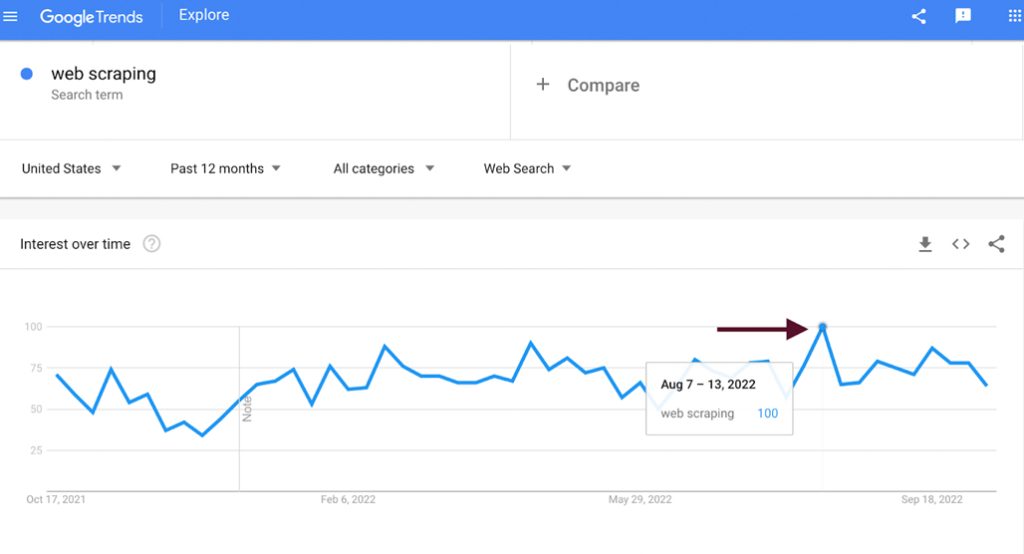
It's not illegal, but it's against policy, with one exception: if you're harvesting what amounts to personal protected information from Google Trends, that information is protected under laws like the GDPR. Google isn't going to sue you over it, but if you use that data in a way that traces back to you and the person who is identified chooses to, they can take action against you.
Google isn't generally going to take action against you specifically. What they will do, though, is monitor your actions, and if you violate rate limits or try to get around access restrictions, they can restrict or ban your IP addresses from accessing Google Trends data. Which leads to the next question:
Do You Need a Proxy for Google Trends Scraping?
Yes. In fact, you generally need a list of proxies to rotate through. The more requests that come from a given IP address in a short time, the more likely it is that Google will block those IP addresses, either temporarily or permanently.
You also want to avoid using headless agents. A headless agent is an agent or access method that does away with all the extraneous scripts and unnecessary rendering (so, things like cURL or headless browsers) to speed up scraping. After all, you don't need the page to look pretty if all you need is the data underneath it, right?

Unfortunately, Google will detect and restrict these kinds of browsers and agents. Why? Because they're pretty much never used for anything other than scraping. Normal web users want that rendering so the pages are usable.
Instead, what you need are residential proxies. Many lists of proxies are just lists of IPs from server farms or data centers, and it's very easy to distinguish them from real traffic, so Google can block them with ease. Residential proxies come from sources laced throughout residential neighborhoods and individual users, making it a lot more difficult for Google to detect and block them.
It's not enough to just use a single residential proxy IP, either. You'll want to rotate through a list of them so you don't have a string of obviously robotic queries happening from the same IP on a regular pattern. There are certainly ways to obfuscate it, but the best is to spread out your requests through a variety of IPs. Some domain extensions and IP sources are more easily flagged than others, so diversity matters.
What are the Google Trends Rate Limits?
Google doesn't publish their rate limits since there's no official API, so you should realistically never hit them as a legitimate user. As a scraper, though, you can run into them and end up rate-limited.

Pytrends has this to say:
"One user reports that 1,400 sequential requests of a 4-hour timeframe got them to the limit. (Replicated on 2 networks)
It has been tested, and 60 seconds of sleep between requests (successful or not) appears to be the correct amount once you reach the limit."
So, that's a good threshold to keep in mind as a cap to avoid hitting.
Why Not Skip the Trends Altogether?
If you're using Google Trends to gather information and ideas for content you could produce, why bother? For one thing, everyone and their content-marketing mother is using it, so you're not really going to be ahead of the game. For another, I've always found trend chasing to be an exercise in frustration. Relatively little of the traffic you get from it actually sticks around, so it can be very hard to grow without dramatically increasing the volume of content you produce (think news aggregators publishing dozens of stories an hour). Evergreen content is so much better.
Honestly, the best option is to just use Topicfinder. I'm a pro content marketer with over a decade of experience, and Topicfinder is a tool I developed internally to help me achieve success for both myself and my clients. It's packed with useful features, and it's a lot better than relying on the same basic tools everyone else is using. On top of that, I've recently added a free trial, so you can give it a shot and see how well it works for you.
Drop me a line if you need hints and tips on how to get the most out of it (or if you have feedback to improve it); I'd love to chat!
Related Posts



Leave a Comment
Comments


Fine-tuned for competitive creators
Topicfinder is designed by a content marketing agency that writes hundreds of longform articles every month and competes at the highest level. It’s tailor-built for competitive content teams, marketers, and businesses.
Get Started
Thanks for the great article. Regarding programing with pytrends and the usage of Third-Party APIs. I think most suffer from rate limits.
Hey Mo!
I agree; the best systems I've seen are ones that are built in-house in Python. I won't say all of the ingredients but it looks something like this:
- Python core using multithreading and pools
- Undetected Chromedriver, or some other modded version of Selenium
- Rotating residential proxies
- Smart retry logic in-case of captcha or connection issues (or implement captcha-busting API)
Most of the Python libraries out there are 90% complete and need a little bit of work to make them do what you want them to do. But it shouldn't take a developer very long at all to build something like this with all of the great libraries already available!
It depends on the amount of data that you need to scrape and if this is for a small personal project or a larger public-facing application.