5 Ways to Automatically Extract Keyword Ideas from Reddit
![]() Written by James Parsons • Updated April 29, 2026
Written by James Parsons • Updated April 29, 2026


Changes to Google over the years have led to the meme of everyone just appending “site:reddit” to their searches. While it’s not really true (many people actually just go to Reddit to search directly instead), one thing is: Reddit is a churning sea of user engagement. That means tapping into it has the potential to give you incredible insights into trending topics and content ideas you can use in your marketing.
In the past, one of the best ways to get this data was just using Reddit’s API. However, in the last few years, Reddit has made some big changes to that API, leaving a lot of the old methods (and the older content written about them) obsolete.
I wanted to take a look at Reddit-based keyword research and explore the methods currently available. What I found are these five ways to extract keywords from Reddit automatically. What you do with them is up to you (and a matter for another post); my concern here is just getting the data.
Key Takeaways
- Reddit’s hidden .json endpoint lets you extract raw post data by simply adding “/.json” to any Reddit URL.
- LLMs can cluster Reddit keyword data, but results vary by model and require deduplication and filtering beforehand.
- Google Alerts supports Reddit site operators for passive keyword monitoring, though indexing delays can range from hours to days.
- Paid tools like Threadlytics, SnitchFeed, and F5Bot automate Reddit monitoring, with pricing ranging from free to $400+ monthly.
- Apify offers 650+ pre-built Reddit scrapers, combining flexibility of custom code with reduced setup work, though costs can escalate.
Option 1: The Hidden Endpoint
The first option is using the so-called “hidden” .json endpoint of Reddit. This isn’t really some super secret; it’s just a part of how Reddit works on the back end. You can find references to it from a decade ago, so it’s pretty unlikely that it’s going to change any time soon.
The trick is making use of the endpoint.
First, you can take a look at the endpoint itself. All you need to do is go to a Reddit page, which can be an individual thread or a whole subreddit. Then, just add “/.json” to the end of the URL. So this:
- https://www.reddit.com/r/SEO
becomes this:
- https://www.reddit.com/r/SEO/.json
What you’re given depends a little on how your browser handles raw JSON information. By default, Chrome will just show you a big mess of data, and you can click a little box at the top that says “pretty-print” to add line breaks to make it more readable. Firefox gives you more robust web developer tools by default, and formats it all more nicely.
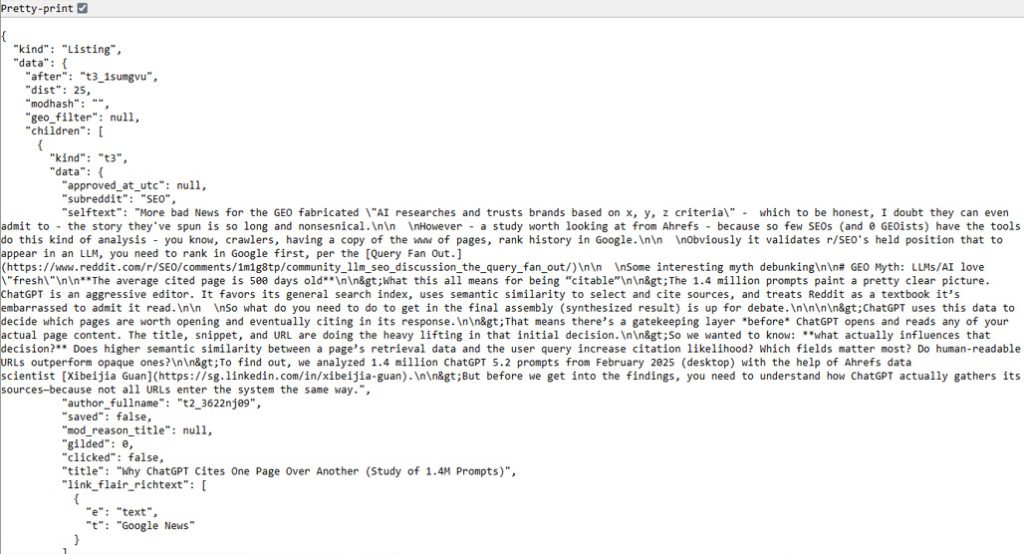
So, what is this data? It’s JSON-formatted information about the Reddit page. In the case of the example above, it’s everything on the front page of r/SEO. But, there’s a lot more to it than just what you see on the page.
What else do you get? Information about your own behavior, like whether or not you’ve clicked a link before. Hashes for the post data. Sources for the links. Alt text and alt links. Image preview sources and dimension data. Author information for who posted the links. All sorts of other data that might not even be there, like if a user was banned and when, if a post was removed, and more.
Obviously, 99% of this is useless. So what do you do with the JSON data? Well, you need to parse it and extract relevant information.
Since this JSON data has existed for years, there are also many, many tutorials for doing this out there online. Modern, recent versions tell you to run it through an LLM. Older versions give you tips for writing your own Python code. I prefer the latter, since you don’t need language parsing for data extraction. If you’re looking for ways to use Reddit to find high-traffic blog post ideas, this kind of data can be a goldmine.
I’m not going to go deep into Python here (this is just option one of five, after all), but I do think that this guide is quite solid. You may have to adapt it to the specific data and names currently in use, and you might not be able to use the API method to get the data, but once you have the JSON, parsing it is relatively easy.
All of this assumes you’re willing to do a little codework. If you’re not comfortable with your own programming, you can try one of the other options.
Option 2: LLM Clustering
A second option is to use one of the major LLMs to extract data from a subreddit of choice, pull meaningful keyword data from the information you feed it, and cluster the keywords you get.
The first thing you need to do is get data from a subreddit. You can do this with the JSON file in the same way listed above, or you can use the API. Since I already covered the JSON method, let’s talk about the API.
Reddit’s API has gotten a lot more draconian over the last few years than it used to be. It used to be fairly easy to access, but these days you need to make an app, register authentication tokens, adhere to strict rate limits, and keep to a hard limit on how far back you want to scrape.
By default, when you call on the Reddit API for subreddit post data, you’ll get the most recent 100 posts in your chosen feed. You can get specific data from each of the sorts (so best, hot, new, top, and rising), so you get 100 posts per feed, though a lot of that is going to overlap.
You can also use pagination code in your API calls to get page 2, page 3, and so on, for additional hundreds of posts in each feed. This works right up to 1,000 posts. If it’s older, it’s out of reach, at least from easy API calls.
Fortunately, since we’re looking for keyword information with an eye towards useful, potentially trending keywords, we don’t need the historical stuff. There are ways to get it, but that’s outside of today’s purview.
This post is a pretty good overview of how to use the Reddit API to grab all of this data. You’ll just have to ignore all of their CTAs to use their data engine instead (or use it if you like, I don’t know if it’s good or not, I’m just there for the blog post.)
Then what?
Well, now you take the big pile of data you got, and you bring it to your favorite LLM and ask it to do some magic black box shenanigans and give you the most useful keywords.
Realistically, you’ll want to take this in multiple steps. First, deduplicate the data. Then, pare it down to remove anything that isn’t relevant. From there, process it to extract the keywords, and then cluster those keywords.
You can do most of this with code instead of an LLM if you like. That might be relevant if you want to save on LLM API credits. You can also use shell tools like KeyLLM for similar purposes.
One major choice you’ll have to make here is which LLM to use. All of them are going to give you different results, and the rate of inaccuracies, hallucinations, and missed keywords will vary. In fact, you might even want to run the same procedure through multiple LLMs to get as much data as you can.
You’ll note that I’m not recommending a specific LLM here. That’s because the whole LLM space is changing so quickly that by the time you read this, the best LLM for the purpose may have changed, and the one I recommend might have been deprecated. Moreover, a lot of it can depend on how you format the data you give the LLM, and how you prompt it to extract value. There’s a ton of data engineering theory that goes into this, which I don’t have time or space for here (or, frankly, the expertise), so I’ll just say: pick the one you like and see what you get.
Option 3: Google Alerts
What if, instead of mucking around with JSON files and raw API data, you could just not do that?
Google Alerts is one of those tools that comes into favor and falls out of favor on a regular cycle, as people rediscover it, use it for a while, drop it in favor of new tools, and forget about it again. All the while, Google has quietly allowed it to continue to exist.
I like Google Alerts a lot as a tool to just have running passively, something that periodically emails me when something new comes up, and otherwise doesn’t require my attention. I’ve also written about it for seasonal keyword research, which you can read over here.
In this case, you want to monitor just Reddit for useful keywords. Fortunately, it’s pretty easy. Since Google Alerts basically runs on the same input logic as Google Search, you can use Reddit site search operators in the Google Alerts box.
The simplest version is to just set up a Google alert for your subreddit of choice, and be notified when new posts are indexed in that feed. That’s fine, but it’s not tangibly different from subscribing to the sub and just checking your Reddit account.
So, further refine it with keywords. You can watch for brand mentions, industry keywords, or anything else specific.
There are two main downsides to the Google Alerts method. The first is that you kind of have to know what you’re going in to get, which means you aren’t necessarily discovering anything new. You can get related and clustered keywords and topics, but you need the seed.
The second is the delay. Google doesn’t have a direct pipeline to Reddit data (no firehose here), so they have to crawl and index just like normal. That means some subs can be on a few hours of delay, and others can be a few days.
Fortunately, it’s easy and free to play around with Google Alerts, so you can set up some alerts that work for you, and just get your digest in your email when there’s something new.
Option 4: Reddit Monitoring Tools
So far, I’ve given you a bunch of ways you can build a tool to monitor and find keyword data from your favorite subreddits. The bright side is, they’re basically free (when you ignore things like LLM credits), and they’re eminently customizable to your needs.
The downside is that you have to do all the work.
Fortunately, other people have also done all the work and offer their own products for use. As business tools, they’re going to cost money to use, but you save a lot of time and effort and development work, and that shouldn’t be underestimated.
What tools can you consider? There are a lot of them out there, so feel free to take your pick.
Reddinbox. This is an agentic AI filter that scrapes Reddit data and looks for trending topics, provides sentiment analysis, and even includes some Quora scraping for good measure. It has one paid plan at $40 per month.
F5Bot. A much older tool that has existed since 2017. It’s basically a more focused version of Google Alerts, scraping sources like Reddit and RSS feeds you specify, looking for your chosen keywords. It has added AI semantic alerts recently as well. They offer a free plan, pro plans at $15 and $60 per month, and a larger enterprise plan for those who need it.
SnitchFeed. This is a more comprehensive social listening and alerts app that covers Reddit and a range of other sites, including LinkedIn, Twitter, and Bluesky, with several more like YouTube, Hackernews, and GitHub planned in the future. It has a very nice dashboard with a ton of information as well. Pricing starts at $36 per month and ranges as high as $400+ monthly for enterprise plans.
Threadlytics. One of the more powerful Reddit monitoring and analytics tools, this one can show you a lot of useful topic and keyword information, along with handy metrics like share of voice, brand sentiment, and opportunities. Pricing is hidden but reportedly starts at $99 per month.
You can also use more focused tools to automate some marketing. I’ve seen people recommend Bazzly, for example; it’s a tool that searches for your keywords and auto-replies or auto-DMs with a CTA. It’s probably not kosher according to Reddit’s ToS, so use it with caution, though.
Option 5: Apify’s Scraper Apps
I’ve saved this option for last because it’s something of a hybrid of everything else I’ve talked about.
Apify is a very robust tool that works sort of like something like Zapier, allowing you to connect various APIs and handle data processing between them. The difference is that it’s much more flexible and customizable. You can build and deploy your own “actors”, which are the scripts and applets that access and handle the data you want. Meanwhile, Apify handles all of the things like scraping and basic data filtering to save you time.
Critically, though, you don’t have to build them yourself. That’s because Apify is pretty popular as a scraping tool, and there are over 650+ Reddit scrapers already available on the site. Some of them are free, many of them have small fees attached, and a lot of them overlap in features, but there are a ton of options you can browse through.
One tricky part is the pricing model. Apify has you pay for a plan with them, which then gives you credits to spend on the Apify actors. That covers API credit costs and, where relevant, dev pay. The cost-per-credit is lower at higher-tier plans, and you get more system resources to run them, but it can get quite expensive if you aren’t sure of what you’re doing.
Still, it’s one of the best options if you’d rather have a tool to do what you need, but the more specific tools above don’t fit the bill. And the option to custom-code your own can’t be beat. Give it a look!
What about you; do you have recommendations for getting Reddit keyword data? I know there are more tools out there, as well as some other options, so feel free to leave your thoughts in the comments.
Related Posts



Leave a Comment


Fine-tuned for competitive creators
Topicfinder is designed by a content marketing agency that writes hundreds of longform articles every month and competes at the highest level. It’s tailor-built for competitive content teams, marketers, and businesses.
Get Started