The Best Free Scraping Programs for Windows and Mac
![]() Written by James Parsons • Updated April 15, 2026
Written by James Parsons • Updated April 15, 2026


There comes a time in the career of every marketer when you need to gather a lot of data from a lot of web pages very quickly. It’s extremely tedious and also extremely easy to automate, so of course, it makes sense that software is available to do it for you. The question is, which of these programs are the best, most useful options?
To some degree, it all depends on what you need. Different web scrapers will give you different degrees of freedom and different limitations, often based on what they want to hide behind a paywall. Even that - the cost - can be a significant factor.
Today, I want to talk about free scraping programs specifically. That means some options you might like aren’t going to be on the list, because they cost money. I’ll also include some that have free and paid versions, talk about their limitations, and compare them to other free tools.
Key Takeaways
- Greenflare is the top recommendation: completely free, open source, no crawl limits, powerful filters, and CSV exports.
- Several tools like Screaming Frog and Data Miner offer free versions but impose strict limits, often requiring paid upgrades.
- Three tools-HTTrack, Cyotek WebCopy, and SiteSucker-focus on downloading entire websites locally rather than targeted data scraping.
- Scrapy is the most customizable option but requires Python knowledge, making it unsuitable for non-technical users.
- Key evaluation factors include update frequency, data types collected, ease of use, and whether the tool runs locally or cloud-based.
What to Look For in a Scraper
If we’re talking about free web scrapers, you want to know how to evaluate a program before you set your system resources to scraping data that ends up incomplete. Other than price - since we’re talking about free programs today - here are some things to evaluate.
- How recently was the program updated? The longer it has been since the last update, the more likely it is that a scraper won’t work on modern-designed sites.
- What data does it scrape? Some scrapers can harvest much more information than others.
- How limited can you make it? Sometimes, you don’t want or need 10,000 individual pieces of data about every page you scrape. How well can you limit it to just what you want?
- How easy is it to use? Some scrapers are incredibly powerful but require you to essentially know how to code to use them, while others are as simple as some checkboxes in a GUI.
You might also want to look into how it runs. Some scrapers are local-only, meaning you have to tie up your system resources and use your own IP to do the scraping, which can occasionally have repercussions if a site blocks your IP because of it. Cloud-based scrapers can be harder to set up because you need a server that can manage it and allow it - which not every host will - and they often limit cloud access behind a paywall. Hybrid options can be configured either way, and there are also browser-based scrapers as well.

You might also consider whether you’re scraping at the code or no-code level. Code-level scraping pulls data directly from a website’s code but can be confused or leave out data hidden or generated by scripts. No-code scraping scrapes what you see in a finished and rendered web page, which can be slower but is often more reliable.
Finally, there’s a new generation of AI-powered scrapers currently being developed. I’m hesitant to use them, because I inherently distrust the accuracy of AI, but I believe these are more accurately described as ML-based, or simply no-code scrapers with broad matching, so calling them AI is more for marketing than accuracy. Still, it’s worth thinking about once the field has narrowed and a few winners have come to the top.
Let’s get started!
Screaming Frog
Website: https://www.screamingfrog.co.uk/seo-spider/
Platforms: Windows, Mac, Linux
Screaming Frog is only on this list because of name recognition. It has a free version, but it’s limited to 500 URLs, which is a pretty strict limit when you have a lot of research across a lot of sites to do. In a lot of cases, even a single blog can eat up all 500 URLs, and you’re left with a very limited selection of data.
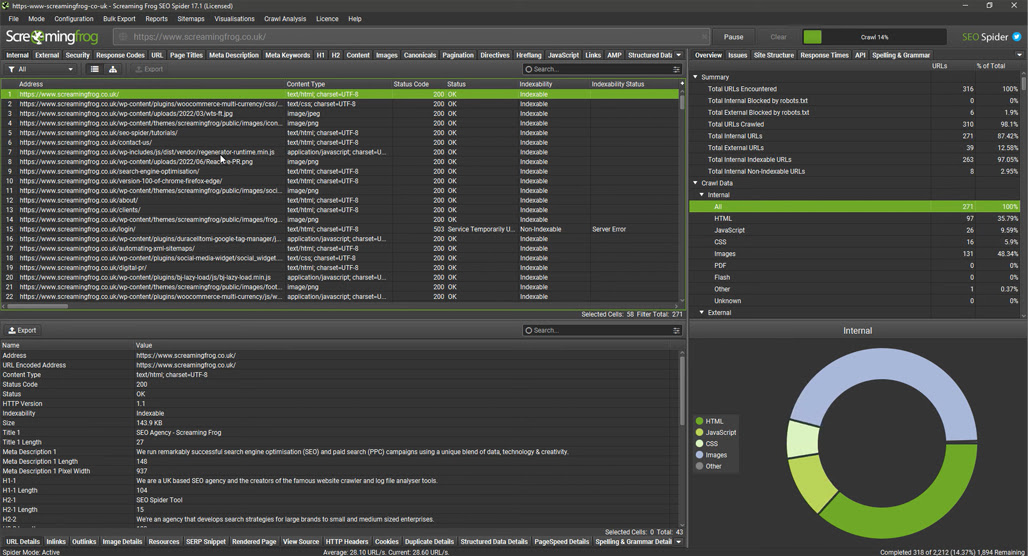
I just know that if I don’t mention one of the oldest names in web scraping, someone would point out the free version exists, so I need to bring it up. These days, I don’t think it holds up compared to other free options on this list.
HTTrack
Website: https://www.httrack.com/
Platforms: Windows, Linux
HTTrack is actually a step beyond a web scraper. Web scrapers tend to harvest specific kinds of data, such as the title tags, meta data, and link anchors for every page you feed into it. HTTrack goes a step or three further, and simply downloads the entire website into a local directory on your machine. Everything - the HTML, the images, other media files - is downloaded.
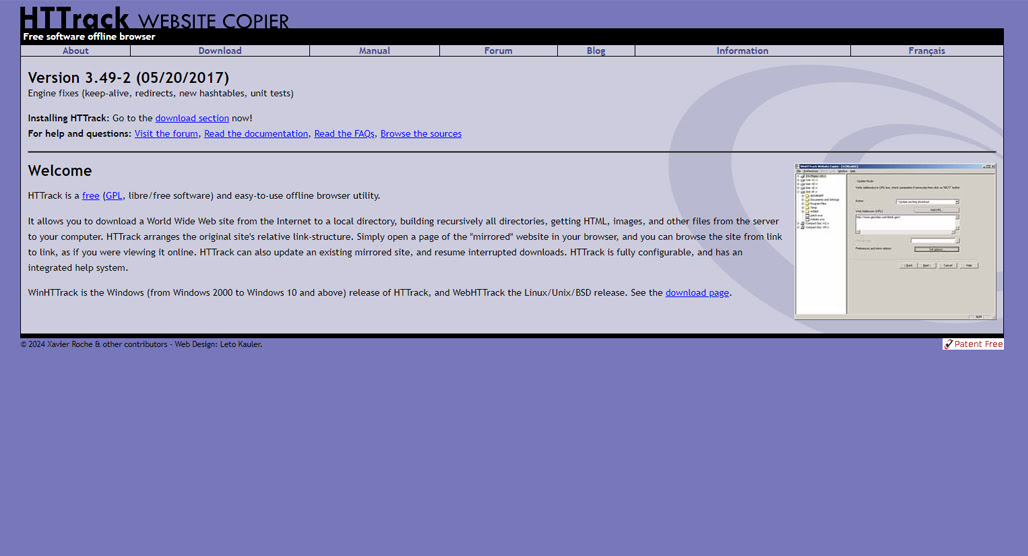
What’s interesting is that HTTrack has been around for a very long time. The original version was designed as an “offline web browser” and was released all the way back in 1998; the creator has continued to maintain it to this day, and the most recent stable release as of this writing was January 2024. It’s also open source and licensed under GPL.
By default, HTTrack obeys robots.txt directives since it operates like a web crawler. That means, depending on the site you want to scrape, some parts may be excluded or hidden from it. You can override this, though, so it’s not a huge problem unless you don’t realize it’s happening. Often, the blocked pages aren’t useful for marketing anyway - they’re things like system pages and file pages, so they aren’t very useful - so you often don’t even need to worry about it. If you’re concerned about others doing the same to your site, you can block your site from SEO tools and scrapers as well.
Cyotek WebCopy
Website: https://www.cyotek.com/cyotek-webcopy
Platforms: Windows
Cyotek’s WebCopy is effectively the same thing as HTTrack; it’s an “offline browser” and website downloader. It does automatic code rewriting to change references from online resources to local resources (such as if a page references a CSS file, the reference changes to the locally downloaded CSS file instead), and there’s a lot of configuration available to include or exclude certain media.
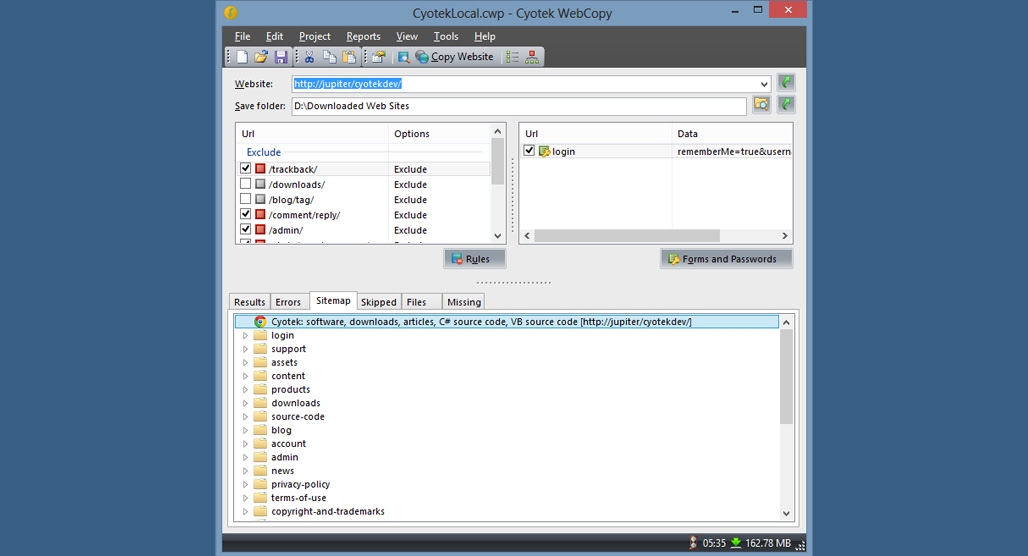
Unlike HTTrack, WebCopy does not parse JavaScript or virtual DOMs, so dynamically generated content, script-based sites, and other kinds of websites won’t be truly copied. It also doesn’t download raw source code, just the post-processed pages, sort of like how a caching plugin generates a version of a page to serve rather than having the browser re-render it every time. If a competitor copied a page on your site, this is the kind of tool they may have used.
Overall, if you want to go the “offline download” route rather than a scraper-and-spreadsheet route, I think HTTrack is the better option.
SiteSucker
Website: https://ricks-apps.com/osx/sitesucker/index.html
Platforms: MacOS, iOS
SiteSucker is the third (and final) offline site downloader on this list. I include it because it’s available for Mac devices, unlike the other two. I have no real idea why you would want to use it on an iPhone, but the option is there if you want to.
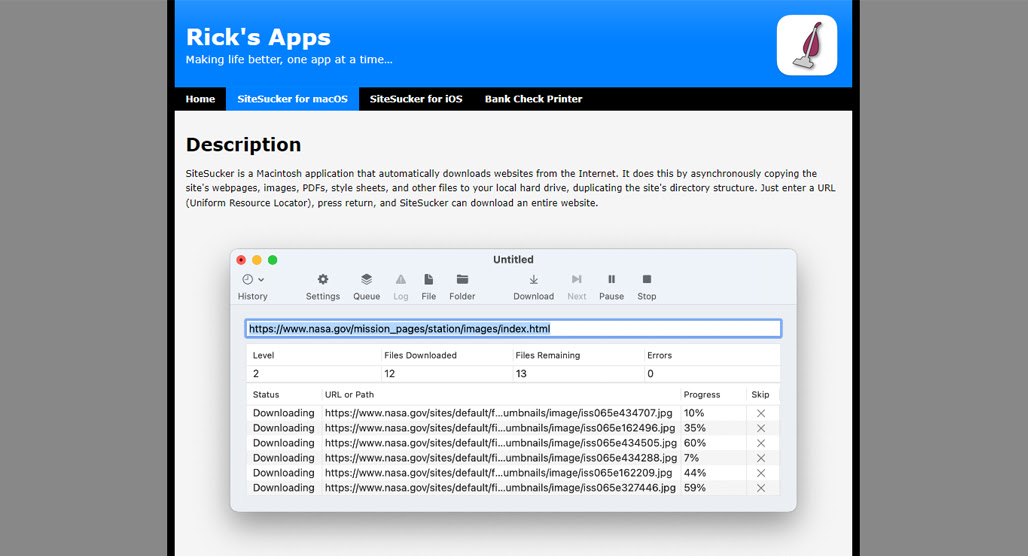
It has the same set of features, essentially, as WebCopy, including the localization of file paths. It is a little more limited in that it won’t download videos unless you use the paid version, but that’s the only real limitation. If you’re on a Mac and want to track your keywords on MacOS alongside your site downloading workflow, there are free tools available for that too.
Data Miner
Website: https://dataminer.io/
Platforms: Chrome
Data Miner is a somewhat limited but extremely free-form scraping tool. It’s a browser plugin for Chrome, pre-loaded with scraping recipes, like “scrape contact information and emails from this page,” but it also comes with a recipe builder so you can click a button, perform an action, and replay that action as a scrape. That’s how it’s extremely customizable; you’re able to customize whatever scraping you want in just a handful of clicks. It also proactively tells you if the site you’re on can be scraped since some will have roadblocks that would mess with your data.
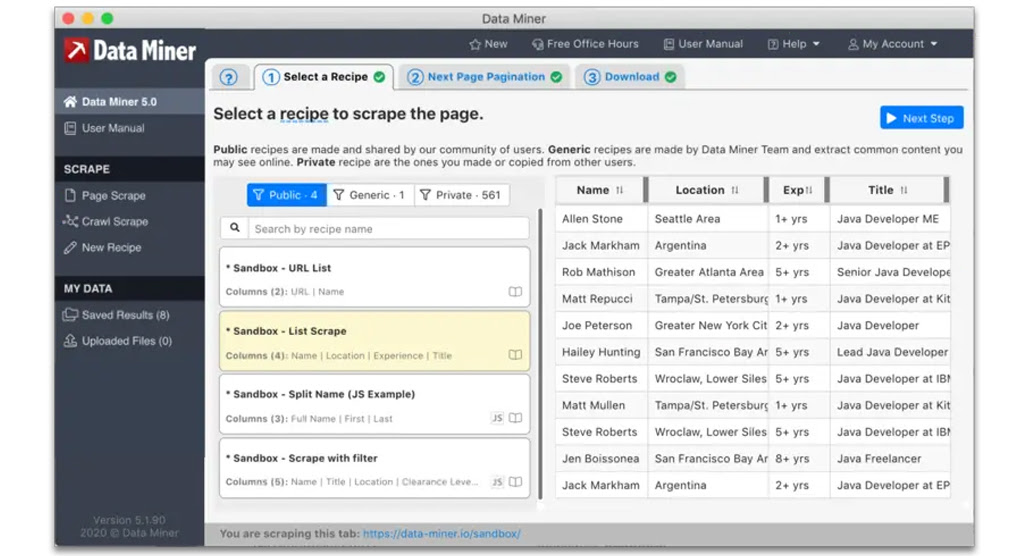
The limitation I mentioned is on the pricing. Data Miner is free for up to 500 pages scraped per month. This page count resets each month, but only as long as you don’t exceed it. If you ever, at any point, exceed the count, your access is permanently locked until you pay for a plan. If you’re careful, you can use it indefinitely; if you’re not careful, you’re out of luck.
Still, for custom scraping jobs on specific sites, it can be very helpful, and having it built into Chrome can be very handy.
Greenflare
Website: https://greenflare.io/
Platforms: Windows, Mac, Linux, Agnostic
Greenflare is quite possibly one of the most powerful free scraping tools currently available. It’s open source and completely free, so if you want to get the Python package or the source code from GitHub, you can do so. And, of course, simply downloading the app for Mac or Windows is easy.
Unlike website downloaders, Greenflare is a scraping tool designed for marketers. It’s a lot like Screaming Frog, but where Screaming Frog’s free version is extremely limited, you have no such limitations with Greenflare. There are no crawl limits, powerful filters, a wide range of scraping options, data exports as CSVs, and a whole lot more.
If you choose anything on this list, my recommendation would be Greenflare. It’s super useful, easy to configure and use, and powerful enough to scrape anything you could want. The one downside is if the site you’re scraping has anti-scraping measures in place like rate limits, captchas, or IP blocks, you might need to roll up a proxy list to do your work.
Beam Us Up
Website: https://beamusup.com/
Platforms: Windows, Mac, Linux
Beam Us Up is an interesting case of something that has been around a while, but somehow I had never heard of until recently. The developer made the scraper tool all the way back in 2013 after a long and frankly fascinating history.
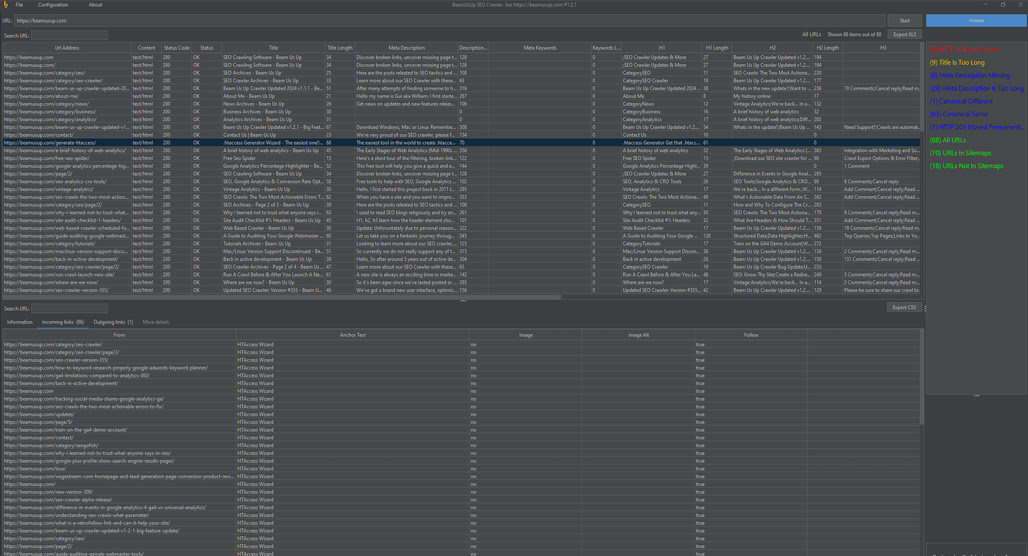
The tool is free, and while it’s not open source, it seems comparable to a lot of other scrapers out there. I will say that the developer, being just a single guy, means updates aren’t necessarily robustly tested, and some people report having issues, particularly on Mac devices. I haven’t run into those, but I also haven’t gone deep into using it yet.
If you’re fine using tools that may have janky support but useful features, giving this one a try isn’t a bad idea. I still prefer Greenflare, but now and then, there’s a need for something new, and you never know when one will disappear or add features you can’t find anywhere else, so keeping an eye out is a great idea.
SEO Macroscope
Website: https://nazuke.github.io/SEOMacroscope/
Platforms: Windows
SEO Macroscope is what I used to recommend before I discovered Greenflare as a free alternative to Screaming Frog. It’s fairly powerful but a little less user-friendly than Greenflare. It’s free and open source, easy to download and use, and as long as you know what all the terminology is and are comfortable poking around in an old-school style application, it’s fine.
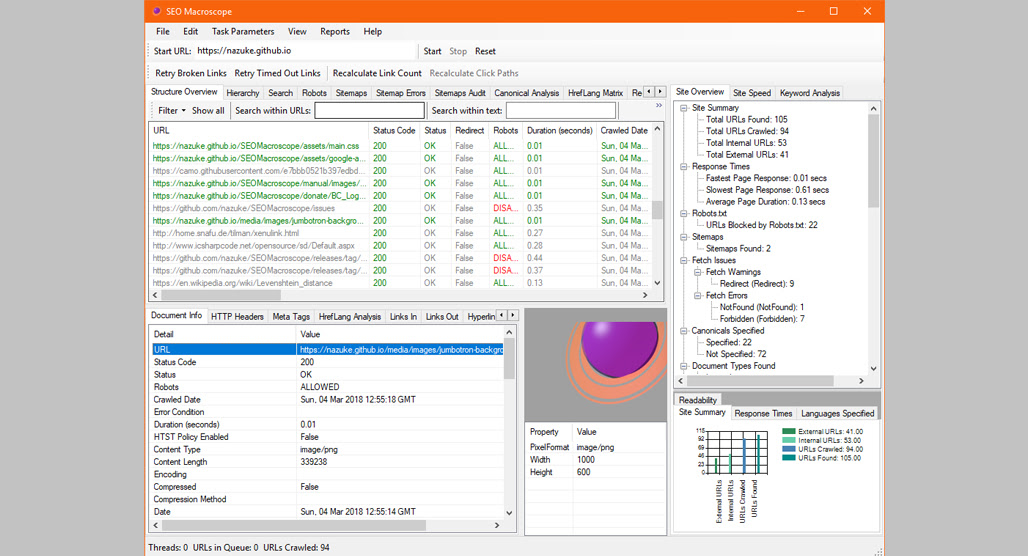
The biggest downside is just that it hasn’t really been updated in years. Some of the features it offers aren’t really useful to scrape anymore, and others you might want can’t be scraped because they were trends or data that didn’t exist when Macroscope was made. It’s quite powerful, though, so if you know what you want to scrape and know it can do it, go ahead and use it.
Scrapy
Website: https://scrapy.org/
Platforms: Windows, Mac, Linux, Agnostic
Scrapy is free and open source because it’s a collaborative project and framework maintained by a large community of SEOs and coders. It’s Python scripting developed to enable a wide range of possible web scraping functions, which you can run locally or in a cloud environment by putting it on a server.

Because of how it works, it’s both extremely customizable and a lot harder to use than just about everything else on this list. You have to know enough code and how Scrapy works to be able to effectively create your own scraper.
If you know what you’re doing, Scrapy is an incredibly powerful engine that can enable any scraping you possibly want to do. If you don’t know your way around Python and scripting, you’re going to have a hard time getting value out of it without a crash course - though tools like accurate website traffic checkers can complement what you build once you’re up and running.
Your Recommendations
I know I’m only just scratching the surface of web scrapers here, so I want to know what your recommendations are. Keep in mind that I’m limiting myself to free scrapers here, so if your suggestion is “free” but is so limited you have to pay to get any use out of it, it’s not really appropriate for this list.
Either way, though, I’m always on the lookout for new apps to try out, so if you have one I haven’t listed, let me know!
Related Posts



Leave a Comment


Fine-tuned for competitive creators
Topicfinder is designed by a content marketing agency that writes hundreds of longform articles every month and competes at the highest level. It’s tailor-built for competitive content teams, marketers, and businesses.
Get Started