Noindex Blog Posts: When You Should (And Shouldn't) Use It
![]() Written by James Parsons • Updated April 15, 2026
Written by James Parsons • Updated April 15, 2026


Noindex is a powerful piece of technology for managing your blog's indexation with Google. It's also very easy to misuse, and a lot of people don't quite understand what it means and how it works. So, to help you keep from making a mistake - or to identify and fix a mistake you've already made - let's talk about how the noindex tag works, how it doesn't work, when you should use it, and when you should avoid it.
Key Takeaways
- Noindex prevents pages from appearing in search results, but doesn't stop crawlers from loading the page entirely.
- Using both robots.txt and noindex simultaneously can backfire, as blocked pages may still appear in results.
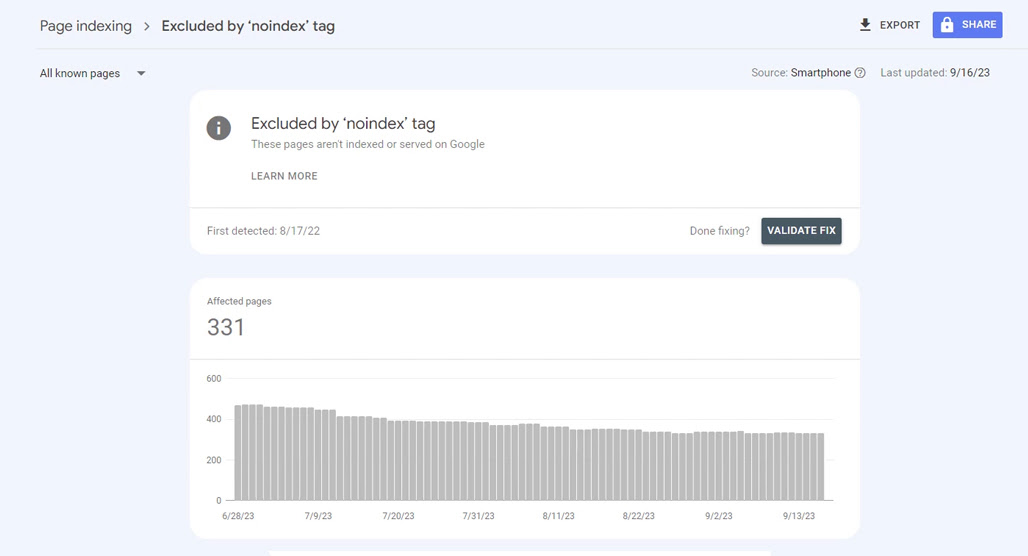
- Good noindex use cases include duplicate content, temporary posts, limited-audience pages, and WordPress attachment pages.
- Noindex doesn't help sculpt PageRank; it simply causes that fraction of link value to disappear entirely.
- Avoid noindexing content you plan to rank later, as Google can be slow to re-index it afterward.
What is Noindex and How Does it Work?
Noindex is an attribute that can be added to a page in the meta tag, or in the HTTP response header. The stated purpose of the noindex tag is to prevent search engines like Google from adding the page to their search index. This then prevents that page from showing up in search results.
Most major search engines respect the noindex tag. If you use it, your page won't show up in Google search, Bing search, Yahoo search, DuckDuckGo search, and so on. Less scrupulous search engines might ignore it, but when you're talking about fringe, dark web, and other scrapers, it's a small fraction of a percent of search results out there, so it's not too meaningful to care about.

Noindex can be specified on a per-bot level. So, for example, you can use a general noindex tag like:
<meta name="robots" content="noindex">
Or, you can prevent a specific bot from crawling the content, such as:
<meta name="Googlebot" content="noindex">
For this second example, remember that since several search engines are based on the mechanics and indexes of others, this can have knock-on consequences. Since Yahoo, Bing, and DuckDuckGo are all essentially the same search index behind the scenes, noindexing content from one of them might not work; you may need to noindex from all of them.
The HTTP response version looks simple, too:
X-Robots-Tag: noindex
There's no functional difference between the HTML noindex and the HTTP header noindex. They both work the same way; it just comes down to which is easier for you to implement on your site. If your CMS doesn't allow you to edit your HTML, the HTTP header may be the only viable option. Or, you may need to use a plugin to manage it.
It's also important to keep in mind that the noindex tag and the nofollow tag are not the same thing. Nofollow is a tag for links that tells Google not to pass link value to the destination, but Google still fully recognizes that the link exists and can even index content on the other end of it.
The Robots.txt Misconception
There's one huge and common misconception about noindex, which is that it's essentially the same as using a robots.txt directive to block the search engine crawler from viewing the content.
When you use robots.txt to block a page, it means that if the web crawler tries to view the page, it will see the robots.txt directive and leave before even loading the page at all.
If you use noindex, the crawler will load the page - or at least the header information - and, when it sees the noindex tag, will stop and disregard the page, removing it from the index.
The issue is if you use both, it might just not work.
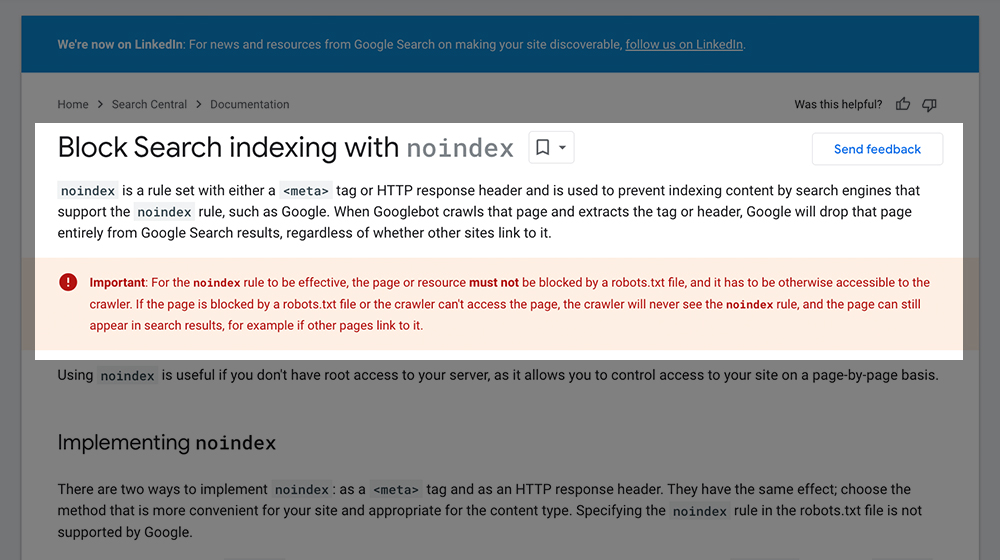
Here's what Google says in their developer documentation:
"For the noindex rule to be effective, the page or resource must not be blocked by a robots.txt file, and it has to be otherwise accessible to the crawler. If the page is blocked by a robots.txt file or the crawler can't access the page, the crawler will never see the noindex rule, and the page can still appear in search results, for example if other pages link to it."
This isn't a super common issue, but it can come up, so make sure you're only using one of the two ways to prevent your page from being indexed (generally, noindex is the better choice.)
One of the most important things to know is that noindex does not prevent the Googlebot from loading your page at all; that's what robots.txt is for. It simply prevents Google from putting the content in its index. If you're running malicious pages, trying to exploit content on other search engines but hiding it from SEO tools and scrapers, or otherwise trying to pull the wool over Google's eyes, noindex is not the way to do it.
When Noindex is the Right Choice
So, let's start by talking about some of the situations where you might want to use noindex.
One of the most common is when you have content on your site that may have some important value but not necessarily to readers. The content might be duplicated legitimately, or it might be thin, or it might be very limited in scope. Think of things like press releases, content you're syndicating from another source, or content you published on a sister blog and are reposting on this blog.
Basically, content that doesn't have much value in terms of pure SEO or even in user value but is still worth keeping around. Maybe you need to keep it because you're paid for the syndication or because cross-posting it is a way to bring awareness between two sites you own or for another purpose. These are good chances to use noindex to prevent duplicate or stolen content issues, but keep the content around for the people who browse your site and see it.
Another common reason is that you have posts that are meant for a limited audience and don't really need to be indexed in Google search results. For example, a news post meant primarily for your employees or an orphan page that needs to exist as a resource but doesn't need to be visible to the wider internet. These kinds of posts can often be handled in other ways - email, logged-in-only visibility, and so forth - but noindex is a good way to help prevent them from escaping containment, so to speak.
Probably the second or third most common reason I see noindex used properly is for posts that are only meant to exist for a few weeks or a few months. Think about things like announcement posts, sale posts, press releases, and other announcement-style temporary posts. These are pieces of content that don't necessarily need to be broadly indexed, but they do need to exist for at least a little while.
Noindexing these kinds of posts can be a valuable way to minimize how many abrupt changes you have in Google's index. Google doesn't really like it when pages show up and disappear frequently because it means your site isn't reliable, and they need to spend more effort checking to ensure your content is available. They hate serving 404s and missing pages, just like web users hate clicking links and finding nothing on the other end.
Another one is attachment pages. This is specific to WordPress; when you upload an image or other piece of media, WordPress frequently creates a specific page for that content. Usually, these are basically hidden system pages, but sometimes they can end up visible, indexed, and a huge problem.
When a site suddenly has 4x-10x the number of pages and a 4:1 or 10:1 ratio of thin pages to real content, it can be a huge penalty waiting to happen. Noindexing the attachment pages is a backup to prevent this from occurring.
Normally, these aren't problematic since a plugin, CDN, or other option will hide them. But if they show up, it's chaos, so try to avoid it if you can.
When Noindex is Usable but Not Ideal
There are also a few other circumstances where noindex is usable - and you won't get punished for it, generally - but it can be a little riskier. These are ways that Google might decide are abusive if you use it a lot or if it's coupled with other techniques that they think aren't valid for modern SEO.
First up are test pages. Maybe you're trying out a new blog post template and you want to make sure the alignment is all right, so you're filling it with copied text from another post, or lorem ipsum text, or another placeholder.
Test pages aren't usually going to be a problem, especially if your test is very short. If you publish the page, take a look at it, make some changes, refresh, and then unpublish it, what are the chances that Google is going to index it in the few minutes you're working on it? Noindexing it prevents that from happening, but it frequently isn't a problem.
That said, test pages can be optimized using preview windows instead of live posts, so there isn't much reason to have to do this. If you really, truly, absolutely need a live internet link for a test page, register a test domain and noindex the whole thing.
Another semi-common and not recommended (by me, anyway) way to use noindex is with guest posts that you need to publish but that you really would prefer that Google doesn't see. Maybe you have a contract that stipulates you need to publish the guest posts - and somehow doesn't stipulate that they need to be indexed - but they're off-topic enough or thin enough that you worry that Google would penalize you for them. It's worth reviewing common guest post rules and guidelines to avoid getting into this situation.
Truthfully, this one is close enough to spam techniques and guest post/link abuse that even a noindex might not stop you from being penalized for it. Google respects noindex, but that doesn't mean they can't see the page. They have plenty of ways of seeing what's on a site other than just their Googlebot.
When it comes to content like this, if you're worried about Google seeing it, reconsider whether you should pay to have your guest posts published in the first place.
When Not to Use Noindex
Now let's go to the far end of the spectrum; the times you really shouldn't use noindex, either because it won't solve the problem you're trying to address, or because it will get you into worse problems.
The first is to hide and remove thin content and spammy pages from the index. In these cases, I ask you: why keep the pages around? If they have some lingering value, then you can work to improve them by rolling several together into a larger FAQ, buffing up the content, or otherwise making them better pages. If they don't have any value, just delete them. I promise it won't hurt your site to do so.
The second is in any case where you're in progress refurbishing content and intend for it to be indexed later. I've seen some people do this with pillar content, only to find that Google is pretty slow to re-index that content. Instead, work on the update in a draft so you can publish all of the changes at once with no gap in indexation.
Obviously, never use noindex on any content you want visible and ranking. Even a temporary noindex, even if it's site-wide, can be enough of a problem for future indexation that it's not worth doing.
Similarly, I've seen some people noindex things like category and tag pages, thinking that they're thin, duplicate, or otherwise not valuable. They're actually quite useful, though, so hiding them removes a potential source of value from your site.
Finally, noindex does not help you "Sculpt PageRank" or otherwise manipulate your SEO values. Google caught onto that strategy over 20 years ago, and it hasn't worked for so long that it's a wonder there are still people who think it's valid.
What actually happens, by the way, is that Google splits PageRank across every outgoing link regardless. Noindexed pages just evaporate that fraction of the PageRank. It effectively just makes your links worth less.
The moral of the story is that noindex is a rather specific tool. It's powerful, and it has consequences, so it can't be used as subtly or as narrowly as some people think. It's also difficult to toggle off later. Overusing it or using it in the wrong ways can lead to pages that don't appear, lost SEO value, and issues that can linger for years as you try to get your site fully indexed.
Related Posts



Leave a Comment


Fine-tuned for competitive creators
Topicfinder is designed by a content marketing agency that writes hundreds of longform articles every month and competes at the highest level. It’s tailor-built for competitive content teams, marketers, and businesses.
Get Started