Guide: How Accurate is Semrush Traffic Estimates and Analysis?
![]() Written by James Parsons • Updated April 15, 2026
Written by James Parsons • Updated April 15, 2026


Semrush is one of the biggest and best site analytics, competitive research, and content marketing tools on the market. It's not entirely my preferred tool - I like Ahrefs a bit more on the whole - but it's easily one of the top five.
With a wealth of data available in the Semrush dashboard, it's easy to view it as reliable and accurate, but is that actually the truth? Does Semrush have very accurate and good data, or does it just present inaccurate data with confidence?
Let's look a little deeper into the issue, why it matters, and what you can do about it.
Key Takeaways
- Semrush shows 94% correlation with Google Search Console data, but median deviation from actual traffic can reach nearly 69%.
- Smaller sites face greater inaccuracy risks; one example showed Semrush estimating 15,000 monthly visits versus an actual 3,000.
- Semrush estimates traffic using nested assumptions about keyword rankings and click rates, creating multiple points where errors compound.
- Compare Semrush data against itself across sites, never mixing it with Google Search Console numbers from your own site.
- Semrush's backlink analysis, keyword research, and technical SEO data are generally more reliable than its traffic estimations.
Is Semrush Traffic Data Accurate?
The answer to this one is a qualified yes.
I say a qualified yes because it's extremely dependent on who is asking. The larger the site, the more likely the data is to be accurate. It can also depend somewhat on where the data is coming from. Semrush gathers data from numerous sources, and some of them are a lot more accurate than others.
To my knowledge, there aren't very many actual studies being published about how accurate Semrush is. Everything I've found is either a personal anecdote for one site (and no one has aggregated these yet) or doesn't provide any real data, just saying, "It's accurate."
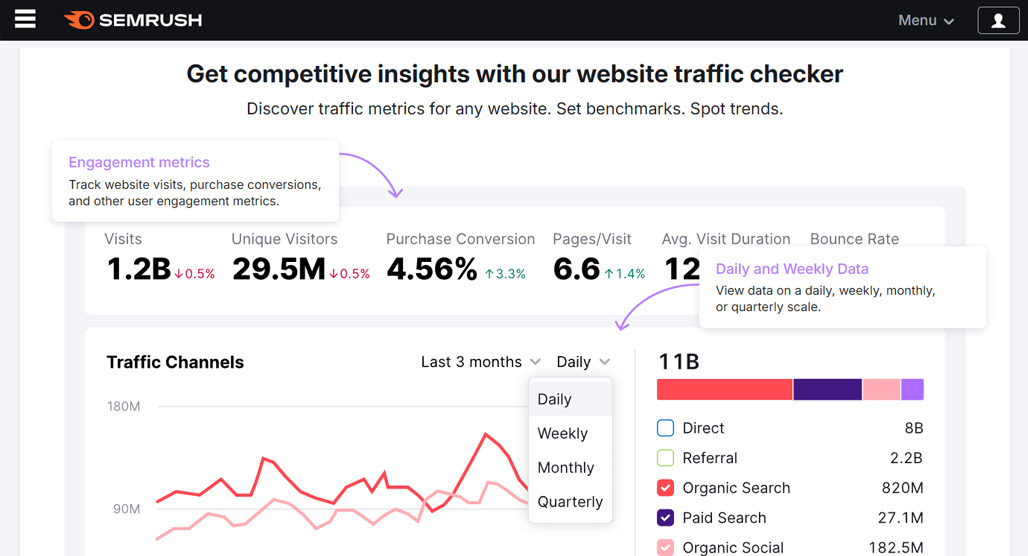
The one actual study with actual numbers and a reputable source comes from Ahrefs, and it's mostly an evaluation of their own data. They just use Semrush as a comparison point. In that study, they found that Semrush has a 94% correlation with Google Search Console data. That's a pretty good rate!
But, there's also deviation to consider. Deviation is how inaccurate a number is when it's wrong. If your site gets 1,000 hits a day and Semrush estimates it gets 1,200 per day, that's a 20% deviation and is pretty good. Ahrefs' study found their own deviation to be just under 50% and Semrush's to be just under 69%.
That's the median deviation, though. Plenty of sites have smaller deviations, but some have much higher deviations.
For my part, since I have access to both Semrush and the analytics data from my clients, I can run some checks myself. Sometimes, yes, it's fairly accurate. But sometimes, you get a site that gets around 3,000 hits per month, but Semrush says it's more like 15,000 hits per month. That's a huge deviation and can make your decision-making very difficult, depending on how reliable you expect that data to be.
Where Does Semrush Traffic Data Come From?
To understand why there's so much variance in traffic data, you need to know where Semrush gets its traffic data from.
The truth is that it tends to be heavily dependent on algorithmic estimations - also known as "guessing" - and statistical comparison. They get some data directly from various sources, but not enough to be completely accurate across the board.
So, first, Semrush can gather data directly from search engines. Google obviously doesn't have a nice API to give data to these tools, so just like Ahrefs and every other big platform, Semrush has to find its own way to harvest it. They claim over 500 million keywords that they watch for things like ranking data, which sounds like a lot, but it's still orders of magnitude lower than what exists in the world or even just in Google's algorithm.
Semrush also has some data from website analytics directly. They get data from clickstream providers, with anonymous data sources. Anonymity means that they can't just associate verified data to specific domains, but they can use the data to get more reliable figures for keywords that can extend to specific site data down the road. I've seen some sources say they get two million recorded "events" per minute, but I can't really verify that directly.
They can also gather data from other available sources, like PPC traffic data. Google's Keyword Planner, various trending topic reports, and other such tools can provide traffic data for keywords and their available search and click volume.
Once Semrush gets the data, they then process it. This is where some of the flaws can come into play and why there can be deviations in a site's traffic data.
For example, if Semrush can't get specific traffic data for a site, they can do things like check what keywords they know of that the site ranks for, check what their rank is, check how much traffic that keyword gets in general, figure out what percentage of traffic the site would get for their rank, and estimate the traffic share. Repeat across all the keywords they know about, and they get the general traffic numbers.
If you can spot a few flaws in this process - namely in the series of nested assumptions - congratulations, you can see why traffic data might not be fully accurate.
The Gaps in Semrush Data
There are three critical flaws in Semrush's data, which are the same flaws any data source other than Google Search Console will have, and a huge part of the reliability of the tool comes down to how well they account for these flaws.
Flaw 1: They don't account for keywords they don't track. One thing I harp on a lot about when it comes to keywords and ranking is that keywords, specifically, can be just about anything. A company like Semrush being able to track half a billion keywords worth of data is nice, but consider what Google can do.
- Look at every piece of text on a site and break it down into any and every potential keyword.
- Spin up natural language processing and find synonyms and related keywords.
- Evaluate a site across all of these axes.
There are over half a million words in the Oxford English Dictionary, and while plenty of them aren't keywords, there are billions of keywords that are made up of multiple words. 500 million keywords is a drop in the bucket compared to what exists out there.
Yes, some keywords get no real traffic and can be disregarded. But, depending on the keywords being tracked and the keywords being left off, the estimated data from a tool like Semrush might be wildly incorrect.

Flaw 2: Estimation models can be distinctly wrong. A lot of traffic data estimations come from first-party sources for all of the traffic a keyword gets, divided across the potential search results and tempered by known click data. But, there are a lot of reasons this can falter.
- Not every search is a click, so search volume isn't necessarily reflective of click volume. Zero-click keywords are a good example of this in action.
- While statistical distributions of traffic across search result positions are fine on average, they can vary dramatically by specific searches. Secondary results, like image results, knowledge graph results, and others, can also muddy the waters.
- Numbers and percentages can be unreliable and can swing with seasonality and trends that aren't reflected in more genericized data.
All of this means that there are a lot of places where the data can go wrong, even if everything is done "right" on a large enough scale.
Flaw 3: The smaller the site, the more a margin of error can swing. Often, the swings and changes are in raw numbers rather than percentages, which means that they impact smaller sites harder than they impact larger sites. That's not to say that the numbers are fully accurate on larger sites either, but that the margin of difference isn't as meaningful.
When you take all of this together, you can see why the data might not be super accurate. That's even before you get into issues like accounting for direct traffic from email or private channels (like Discord, Slack, or Teams messages) that wouldn't be visible.
The other thing to keep in mind is that a lot of the data sources tools like Semrush use aren't real-time or even necessarily updated more than weekly or even monthly. The lower the traffic volume for a keyword, for example, the less likely it is to get frequent updates. Semrush data might not even necessarily be wrong in that sense, but it might not adequately reflect a surge or drop in traffic that occurred more recently.
It's worth keeping in mind that none of this is an indictment of Semrush. It's just the reality we have to live in, where you can only access fully reliable data for your own site (and even then, with Google's analytics using statistical sampling, possibly not even then), and any third-party tool needs to be accounting for the gaps in knowledge and data access. In my view, Semrush does better than most.
How Can You Best Use Semrush Traffic Data?
If Semrush isn't 100% fully reliable - and no third-party tool can be - how do you make use of it? I have a few tips.
First, don't treat it as a hard fact. The fact is, the data you see about your site or about other sites is just an estimation, no matter how accurate of an estimation it is. You can obviously check how reliable it is on your own site but don't assume that it's just as reliable for a competitor's site. Even on similar-sized sites in similar niches, there just might be enough differences between you that it can stand out.
Remember, too, that Semrush has a limited scope in terms of keywords. It's entirely possible that you're ranking for keywords and getting traffic from keywords that Semrush doesn't know about. They try to account for that with their statistical modeling and estimations, but they can't necessarily be super accurate about it.
Second, don't compare apples and oranges. The biggest trap I see people fall into is checking Semrush for a competitor, putting those numbers against your own Google Search Console data, and seeing a huge gap that might feel insurmountable. Instead, you would need to use Semrush on your own site and compare those traffic numbers.
Third, don't assume it's timely data. Semrush's data isn't super reactive to short-lived trends or very recent changes in traffic, so it can take a bit to have those details reflected in their traffic data. Things like seasonal trends, surges of viral interest, and bursty news trends can skew traffic numbers one way or another, and depending on how they impact Semrush in their analysis, it might linger and over- or under-estimate data later.

Overall, Semrush does a pretty good job of trying to account for all of the different data factors, and they're also good at trying to keep improving. It's those improvements to the models that keep me coming back, rather than disregarding their traffic data for another source (since most others are as bad or worse in the exact same ways.)
For smaller sites, Semrush can be great for things like identifying the top pages on a site (so you can scope out competition fairly reliably) and estimating the comparative size of your competitors. In fact, overall, I find Semrush to be most valuable when treating it as a comparative tool, using its own data to evaluate different sites against one another. Truth be told, even when the data is wrong, it's wrong in the same way and around the same scope a lot of the time.
For larger sites, you can usually assume that your data is going to be more reliable. You can also get a lot more out of Semrush's other features, so it can be quite good as a tool once you reach a mid-to-large business size.
Remember, too, that everything I've been talking about is focused on their traffic data. Other data they offer, from technical SEO elements to backlink analysis to keyword research, tends to be more reliable. By all means, make use of that data when you can.
If you want to use something other than Semrush because of all of this, there are plenty of choices. Personally, though, I still find it to be one of the top SEO tools available, and you aren't going to escape the issues with traffic estimations by using another tool. There's a reason they're still one of the industry leaders, right?
Related Posts



Leave a Comment


Fine-tuned for competitive creators
Topicfinder is designed by a content marketing agency that writes hundreds of longform articles every month and competes at the highest level. It’s tailor-built for competitive content teams, marketers, and businesses.
Get Started