Is There a Web-Based Scrapebox? Here's What We've Found
![]() Written by James Parsons • Updated April 15, 2026
Written by James Parsons • Updated April 15, 2026


Scrapebox is one of the most useful tools many people don't quite know about or know how to use in SEO.
It can do a ton of very useful things. You can scrape URLs from search results, page titles from websites, metadata from URL lists, and much, much more. They're also continually adding new features and updating existing features to make them more robust, give you more options for customizing how they work, and much more. And sure, some of their features are a little sketchy - I wouldn't recommend using an automated blog post commenter, for example - but the most useful features are incredibly powerful and ethical to boot.
There is, however, one significant problem with Scrapebox. It's a program you run from your local computer. This has a few distinct repercussions.
- Scrapebox can very easily max out your system in terms of memory, processing power, and even internet connection bandwidth, which both makes your system unusable for other purposes while it's in operation and can hinder the operations of anyone else in the building.
- Some ISPs may prohibit scraping and rapid, intensive connections like that and can throttle your traffic if they catch it.
- Huge scraping operations can take a very long time, and your computer is almost definitely not meant to run that long and that consistently at high usage levels. This can damage your hardware over time.
- You can't access the operation or the data from another computer unless you put the output in a cloud storage location or other shared space. On its own, it's a single-device application.
- Some websites might detect the operations you're performing and, if they're against the terms of use for the site, can prohibit them. You can even be IP blocked or restricted from websites, CDNs, or even Google itself.
Needless to say, all of this is pretty serious. It makes sense, then, that you might want to find an alternative that you can access from anywhere, using the vastly superior processing power and connection bandwidth of a server cluster somewhere, and that doesn't dominate your system or risk your personal access.
Scrapebox itself isn't a web application, but surely someone, somewhere, has made a web-based competitor, right? Let's look at the available options.
Key Takeaways
- Scrapebox is powerful but runs locally, causing hardware strain, bandwidth issues, and potential IP blocks from websites.
- Running Scrapebox on a VPS solves some limitations, offering more processing power and remote accessibility via Remote Desktop Protocol.
- Web-based alternatives like Agenty and WebScrapingAPI exist but have costly monthly fees and strict scraping limits.
- Scrapy is a free, open-source alternative but requires Python coding knowledge, making it less accessible than Scrapebox.
- No single web-based tool fully replicates Scrapebox; different alternatives cover only specific portions of its functionality.
Option 0: Scrapebox
Wait, didn't I just get done saying that Scrapebox isn't a web application? Well, yes, but that doesn't mean you can't run it as a web application under the right circumstances.
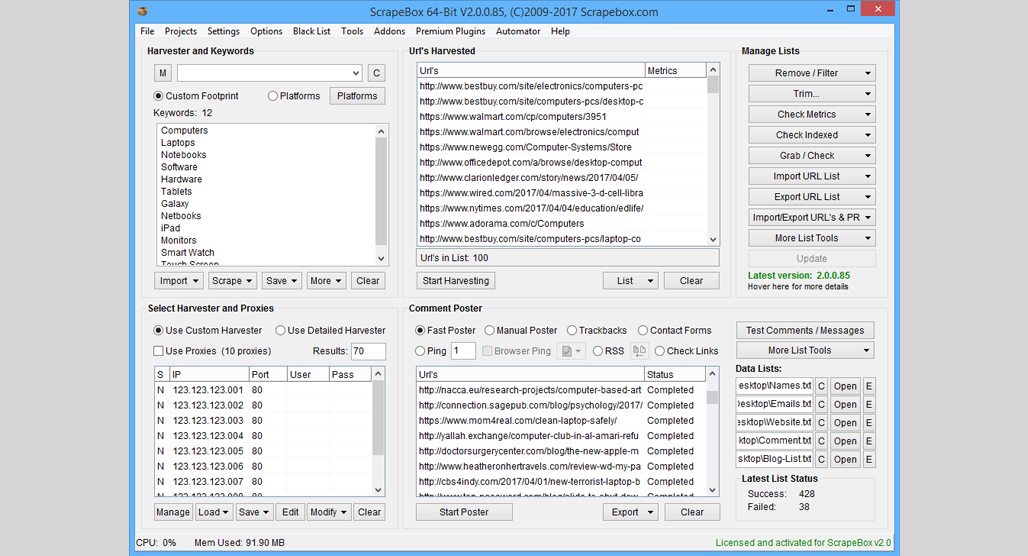
What you need to do is set up a web server known as a Virtual Private Server. This is space on a web server that acts as if it's a private server, where you can set up and run whatever you like on it.
"A virtual private server, also known as a VPS, acts as an isolated, virtual environment on a physical server, which is owned and operated by a cloud or web hosting provider. VPS hosting uses virtualization technology to split a single physical machine into multiple private server environments that share the resources." - Google Cloud.
To set up Scrapebox on a VPS, you need to buy VPS space and a license for Scrapebox. Then, log into your VPS using Remote Desktop Protocol to install it on the server. From there, you can configure your operations and set them running, save the logs on the server, and use the data from anywhere you can RDP into the server.
Many of the same downsides apply here; if a website blocks the IP of your VPS, you're stuck until or unless you start using proxies. However, the VPS will have a lot more processing power and bandwidth than you have on your personal computer. On the plus side, you do get all of the same features as Scrapebox because, well, you're just using Scrapebox. If you're looking for ways to find top keywords in your industry, tools like this can help you gather the data you need.
Option 1: Ahrefs
Ahrefs needs no introduction. It's an extremely powerful tool, a web-based SaaS option with a wealth of data and scraped information in their database. The trick is that the information they give you is always just a little out of date because they aren't live-scraping your results. Instead, they scrape and build an index of the web and draw their information from that.
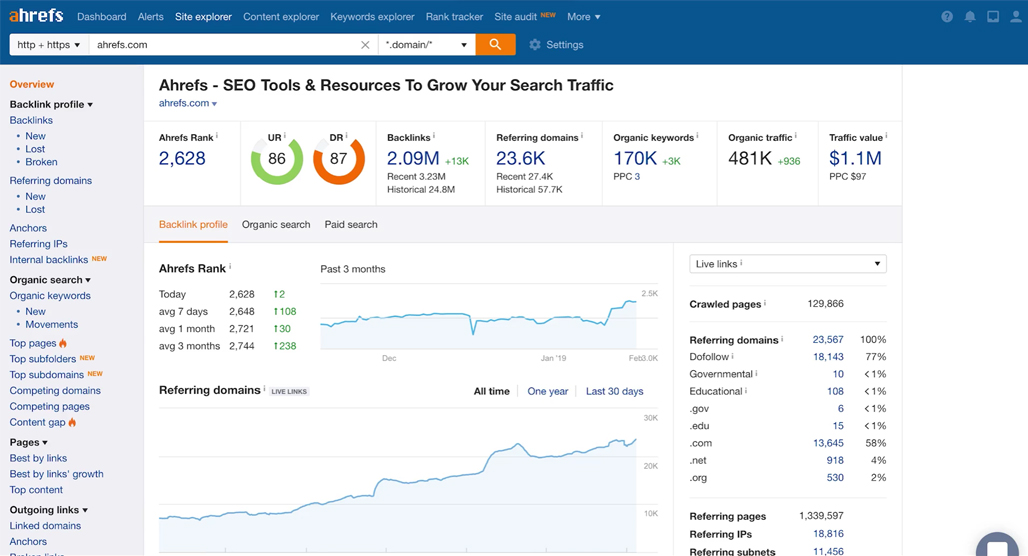
This makes it excellent for top-level information and overall planning, but it's less useful for ongoing tracking, high-detail and granular scraping, and so on. It's also, despite how large and excellent the platform is, still not as robust as Scrapebox for most of what Scrapebox can do.
Option 2: Agenty
Agenty is a web scraping solution with a few very interesting features and a couple of potential deal-breakers, depending on why you want to use it and how. First and foremost, though, it's a SaaS application, so you can use the power of their servers and connection and access your data from anywhere.
One of the big benefits of Agenty is that it's a drag-and-drop system allowing you to use their modules to build a tool to do exactly what you want to do. It can scrape specific data in batches, it can run timed jobs, it can perform monitoring, and a lot more, all customizable to your needs.
They also have integrations with apps like Google Sheets, Dropbox, and Zapier to let you manage and manipulate your data however you like. On top of that, they have an API, so you can develop your own integration to do exactly what you want.
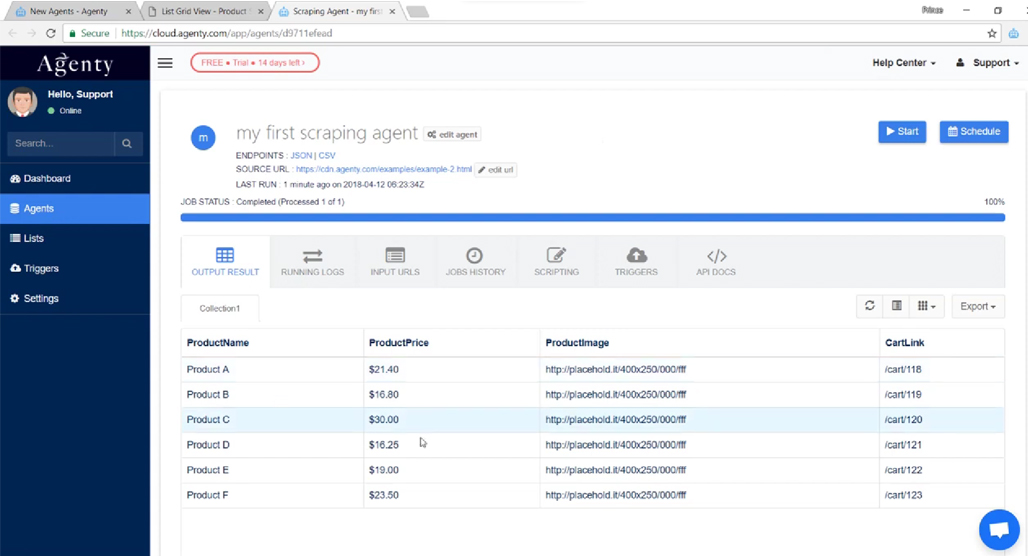
Now for the downsides: unlike Scrapebox, it's a web app with a monthly fee and limitations on how much you can scrape at a time. You have a limit on concurrent sessions/multithreading as well. For example, the cheapest plan is $30 per month, which gets you up to 10 "agents" and a scraping limit of 5,000 pages per month, and you have to export your data because they only retain it for 7 days.
When you're doing keyword research and competitive intelligence work, you can exceed those limits in an hour. The "professional" plan is $100 a month and bumps your scraping limit to 75,000 pages per month, but even that can be a tight limit if you're trying to build lists of tens of thousands of topic ideas.
Now, they will happily sell you much higher or even unlimited caps, but the expense goes through the roof. Compared to buying a one-time license for Scrapebox for $100 (on sale) and paying a small fee for a VPS, you can see why it might be a hassle.
Agenty also isn't quite as robust as Scrapebox. Let's be real here: Scrapebox has been adding and improving features for decades; they're an industry leader for a reason. Nothing is going to stand up to them.
Option 3: WebScrapingAPI
WebScrapingAPI is a company providing a handful of tailored web scraping services, such as gathering business information from various business directories or scraping SERP data for given queries. There's also a general scraping API that integrates proxy servers for diffused access and avoiding rate limits. You can access the Google Search API, the Amazon API, or the general Scraper API.
There are a few downsides to this option, though.
- They provide the API for data, but you mostly still need to make your own scraper. You have to know what you want to get out of the data the API can fetch for you and code up a script to fetch it. This has a bit of a learning curve above and beyond something like Scrapebox.
- Pricing can scale very fast. The basic Scraper API starts at $50 per month and gives you 100,000 API calls, so it's pretty robust compared to Agenty but still far behind the free unlimited ability to scrape whatever using Scrapebox.
You can, however, work with them for managed scraping, where they do all the work and just give you reports with what you're asking for out of it. That service starts at $500 per month but is double that if you want something "beyond the usual data sets," which can have a variety of caveats attached to it.
As long as you're capable of coding up something of your own for the scraping API, this is a perfectly functional option. If you're looking for something with the scraping already coded into it, though - like Scrapebox - you're better off just using Scrapebox.
Option 4: Scrapy
Scrapy is an open-source project for web scraping, collaboratively developed and updated by their community. It's potentially quite powerful and can be run on its own cloud system or your own VPS if you desire.
In a way, Scrapy is almost the exact opposite of Agenty. Where Agenty is a no-code system, Scrapy is an all-code system. You're writing your own web scrapers and running them via terminal code based on Python. It's not exactly difficult, but it's more than you'd have to know to use something like Scrapebox.

One of the best parts of Scrapy is that it's fast, virtually unlimited in what you can do with it, and easy to keep running once you have it configured. It's also very well-documented, given that it's a very popular project with a public GitHub. It's also largely based on the Django web framework, so if you're familiar with that, you're already in a good place starting out. If you want to compare your options, there are several tools to speed up research for writing blog posts that can complement your scraping workflow.
Option 5: A-Parser
A-Parser is primarily a search engine scraper. It can handle all of the major search engines, including Google, Bing, DuckDuckGo, and more. It can scrape SERPs, keywords from sources like Google Trends and Google Keyword Planner, website positions for queries, and even keyword suggestions from search engines.
It's worth noting, though, that A-Parser is similar to Scrapebox in that you need to use a VPS to run it as a web app rather than a local program.
It also has a wide range of useful features for a variety of different kinds of use cases. The reports it generates are great for marketers, for example, and it can help facilitate outreach by a ton. It can also be used for things like monitoring prices on competitor storefronts or scraping ad creative.
A-Parser is both a platform and a toolbox. They have 90+ preconfigured scrapers you can customize to use for your needs, including basic scrapers like Google search results and YouTube search results or more advanced scraper information for platforms like Amazon and Instagram.
The downside is that the primary plan you need for anything other than very basic scrapers is a $300 fee, and it's still not as robust as Scrapebox.
Option 6: Topicfinder
If you take anything away from the options I've listed above, make it this: Scrapebox is an incredibly powerful and versatile tool, and it's not really possible to easily replace it. There are a ton of different tools that can do some small fraction of what Scrapebox can do, and some of them can do it better than Scrapebox, but many of them will either be more expensive, more time-consuming, or just harder to use. Scrapebox really is just a top-tier tool.
That said, I'm very proud of what I've put together with Topicfinder. It doesn't do most of what Scrapebox does, of course, because nothing other than Scrapebox does. What Topicfinder does is scrape the web and the search results for keyword and topic ideas based on parameters you set. You can build lists of anywhere from tens of thousands of results to just a handful. You can scrape them specifically from competitors or from larger and more generic sources. Plus, Topicfinder does one thing Scrapebox doesn't; it can help you evaluate the difficulty and competition of the topics you find.
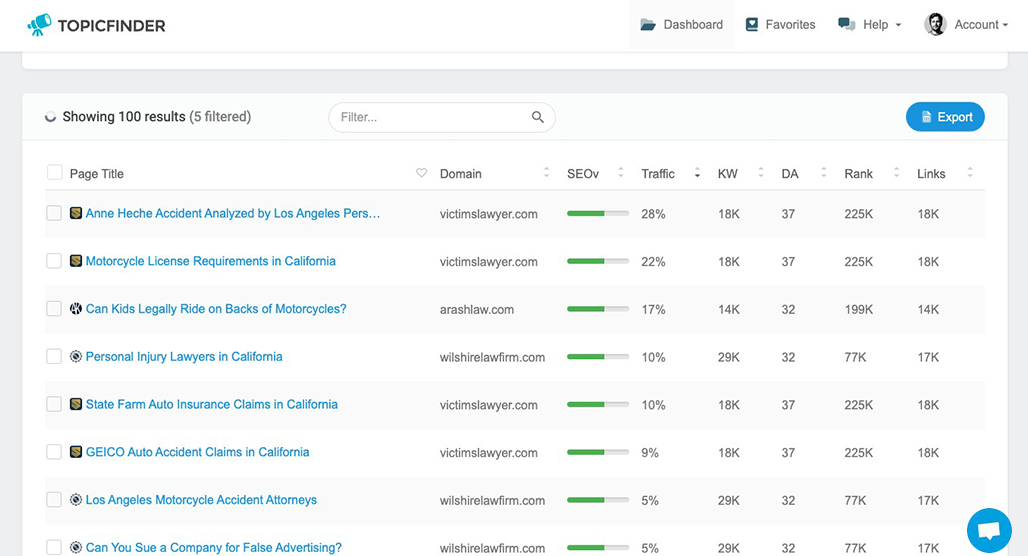
So, what do you want to do with Scrapebox? If you're searching for a backlink finder, a blog commenter, or an email scraper, you might as well go grab Scrapebox and set it up on a VPS. On the other hand, if you're looking for a scraper you can use to get a massive list of valuable, rankable topic titles, I highly encourage you to give Topicfinder a try. With a free trial now available, you have nothing to lose and a ton of potential information to gain.
Related Posts



Leave a Comment


Fine-tuned for competitive creators
Topicfinder is designed by a content marketing agency that writes hundreds of longform articles every month and competes at the highest level. It’s tailor-built for competitive content teams, marketers, and businesses.
Get Started