How to Extract the Post Title from Blog Article URLs
![]() Written by James Parsons • Updated April 15, 2026
Written by James Parsons • Updated April 15, 2026


A big part of modern marketing is knowing not just what you're doing but what the people around you are doing. What are your competitors doing, what are they targeting, how are they covering topics and issues? You need to know information like this so you can know what opportunities exist to bypass, undercut, or outdo their marketing with your own. It's always better to get the data than to make assumptions, after all.
While there are many different tools and methods you can use for this so-called "competitive intelligence" research, one of the simplest things you can do is just scrape through their blog and harvest the titles of their posts.
Sounds simple, right? Well, unfortunately, it's not quite that easy.
- Blog pages can be complex; what is the title and what is a subheading, ad copy, or title-like text at the top you don't want?
- Do you want the meta title, the title in H1s, or both?
- What if the blog in question is split-testing different titles?
- If the blog has been around for years with a regular content marketing plan, are you prepared to spend ages scraping thousands of titles?
All of these and more are common issues you run into when you're trying to harvest blog post titles from your competitors, and that's just for one site. How many competitors do you have? How broadly do you cast the net?
Needless to say, it can become a full-time job just harvesting this data, let alone cleaning it up and making it in any way useful.
So, I've put together a few options you can use to automate and speed up the process.
Key Takeaways
- Scraping competitor blog titles for competitive research is valuable but complex due to bot protection, data quality issues, and scale.
- Custom code solutions face serious challenges including Cloudflare blocking, proxy bans, failed request handling, and messy data requiring cleanup.
- API scrapers reduce technical complexity but cost money, consume credits quickly, and still return unprocessed, cluttered title data.
- Scraper tools like Screaming Frog are industry-standard but considered overkill for simply harvesting blog post titles.
- Topicfinder was built specifically to scrape blog titles cleanly, stripping brand names and cruft, with 100 titles per credit daily.
Before You Begin: Do You Need a List Of URLs?
Before you can start scraping blog post titles, the first thing you need to do is get the URLs from which you want to scrape the titles.
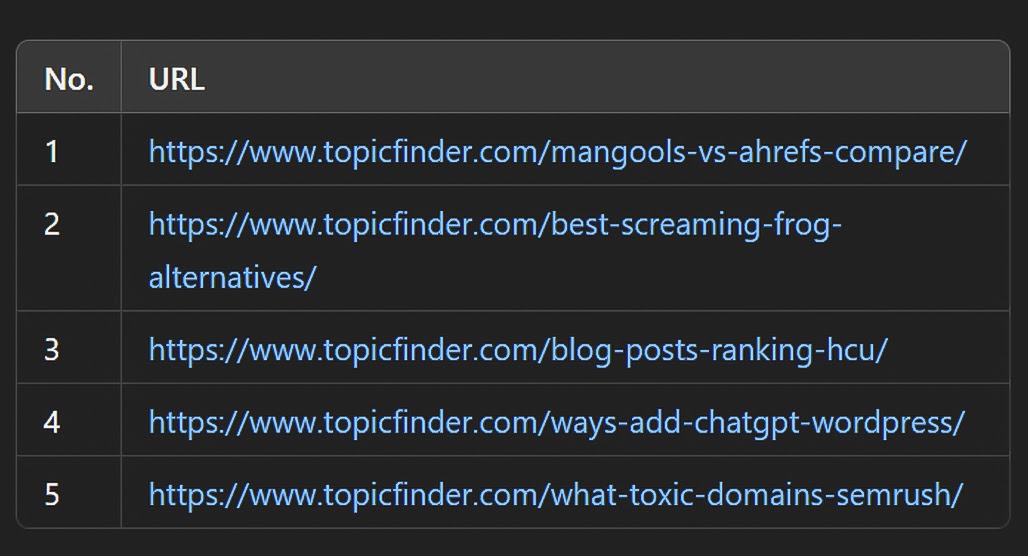
For example, for the last five blog posts I've published (as of this writing), you'd need a document that lists:
- https://www.topicfinder.com/mangools-vs-ahrefs-compare/
- https://www.topicfinder.com/best-screaming-frog-alternatives/
- https://www.topicfinder.com/blog-posts-ranking-hcu/
- https://www.topicfinder.com/ways-add-chatgpt-wordpress/
- https://www.topicfinder.com/what-toxic-domains-semrush/
It's easy enough to gather those manually, but at the same time, you run into many of the same issues. And really, if you're going to manually click through every blog post link on a page, instead of copying the URLs, you could just copy the titles.
If all you have is the blog's URL (like https://www.topicfinder.com/blog/ for me), most of the tools and options I'll discuss later can go through and scrape blog post URLs along with titles as you go. On the other hand, if you already have a list of URLs, you can run it through tools as well.
Basically, you don't need a manual list unless you're building custom code to operate off a list, in which case you will need to use a scraper or build more custom code to build the list. Speaking of, let's talk about custom code.
Option 1: Custom Code
Custom code is powerful. Code lets you do pretty much anything, after all. Python, cURL, PHP, even a JavaScript applet; you can code up something that harvests data on a page relatively easily. There are a bunch of different guides for coding these, like this one for Python, or this one for PHP and cURL.
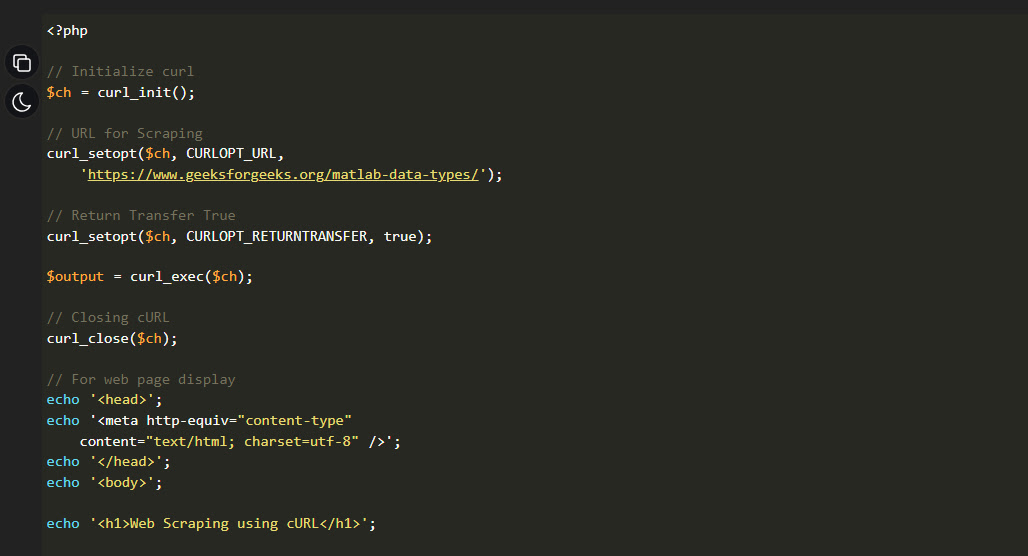
There are quite a few problems with this method.
The first and most important is bot filtering. Many websites today have some kind of protection, like Cloudflare, to prevent bots from spamming and abusing them. It's DDoS protection, security to prevent brute force attacks, and more. Systems like Cloudflare are very good at detecting repeated, systematic, non-human activity (even if it's coming from a human browser and IP) and prohibiting it. They can rate limit you or even block your IP from accessing the site, temporarily or permanently.
There are ways to get around this, of course. The trouble is, they all make custom code a lot more complex. You need to do things like run Undetected Chromedriver or use NodeJS to simulate human behavior in between requests - and even those are getting patched constantly and aren't reliable.
Alternatively, you just accept that IPs will get banned and rotate through proxy servers, though you'll also have to confront the fact that many proxies are already preemptively blocked because others are doing the same thing with the same proxy lists.
On top of that, when a request is inevitably blocked, you'll need some way to retry it. Otherwise, you'll need to restart the app from scratch and either get a bunch of duplicate requests (and probably a faster second block), or you'll need to painstakingly figure out where it left off and get it to start there.
Another issue is even detecting these failures in the first place. It's one thing when the web server blocks your app and sends an HTTP error, but it's another thing entirely when Cloudflare does it. A page that resolves and has a title is a valid target to be scraped, but then you end up with a list of data that looks like:
- The Top 5 Alternatives to Canva for Creating Blog Images
- What is NLP Analysis, and How Do You Use It on Content?
- Just a Moment…
- What is a Content Roadmap, and How Do You Create One?
- Just a Moment…
- Rate Limit Exceeded
- How to Find Alternative, Synonym, and Related Industry Keywords
Those are titles from my blog, but you'll notice a few of them aren't exactly blog posts. A page loads, and it has a title, so the app scrapes it and moves on, but those titles are the titles of the blocks. Cloudflare's block says "Just a Moment…" and many server-based firewalls put the Rate Limit Exceeded text on top.
This also scrapes all data verbatim. Depending on what specific data you're scraping, it might copy icons next to titles, the "- Google Chrome" text from a browser window, or the " | Brand Name" text often appended to titles. All of this needs to be cleaned up at some point to make your data more useful, and that's something you often have to do manually. Regex can help, but you can't get every detail with it.
You should see our Python code just for removing brand names; it's insane. Regex lookahead and lookbehinds, accounting for double pipes or double dashes, dash variations (mdash, regular dash, ndash, etc), converting or normalizing ASCII, foreign symbols, the odd site that uses a bullet • or doesn't add a space after the pipe (|Brand name) - it's a nightmare.
So what else is there?
Option 2: APIs
A second related option is to let someone else do all that work for you and let you scrape it via an API.
This is kind of like a hybrid of custom code and tool solution. Basically, the API owners set up a system that can be used to scrape pretty much whatever data you're after, but you can't just point it at a blog page and tell it to go. You need to code up your own applet to make the specific API requests to get the specific data you want.
You do still need to create your custom code, but you have less work to do and don't need to worry as much about things like proxies and human behavior mimicry.
So what's the downside? Well, consider an API scraper like ScrapeStack. If you want more than a pittance of titles scraped at all, you need to pay for your account, and the credits there can add up pretty quickly. This one is $20 a month for 200k requests, using standard proxies and with basic options.
While $20 might not seem like much (and you probably can do everything you need to in a month unless you're targeting hundreds of sites), there are caveats. The standard proxies are a lot more likely to be detected and have a worse turnover rate than the premium proxies. Requests can be used up when repeating requests or even, in some cases, if you're scraping more than one piece of data from a page. It can be tricky to figure out how far that $20 will take you.
You also don't get any data processing here either. All of the same brand names and browser title cruft can build up in this list of data.
There are lots of these on API marketplaces like RapidAPI, too. If you're looking at more specialized options, there are also different methods to scrape data from Google Trends worth exploring.
My personal recommendation would be to test out a custom scraper on a couple of URLs on any given site you're considering scraping. If you don't have issues, you can keep trying until you have them, or you get everything you need from the site. For any site where you have issues right away, consider setting it aside for the API engine. That way, you save API credits and only offload the hardest work to them.
Option 3: Scraper Tools
Scraper tools are usually the way people go for these kinds of data harvesting needs. Tools like:
- Scrapebox
- Scrapy
- Agenty
- Screaming Frog
- Greenflare
- Xenu's Link Sleuth
- Alternatives to the above
These are all variations of the same concept: a tool, either that you run on your computer or you run via a web interface, that can scrape various kinds of data about a website. It might scrape page titles, HTTP request responses, link status, 404 status, meta information, and more.
If the tool is web-based, it can be a very powerful option, though it's often expensive. If it's a program you download and run locally, on the other hand, it's still very powerful and usually free, but you have the same proxy issues you have with the other options.
The nice part about program-based options is it's coming from your home IP, not a datacenter - so as long as you dial back the speed a bit, you shouldn't get blocked nearly as often as something code-based running on a web server and using a proxy.
Don't get me wrong; these kinds of tools are often industry standards for a reason. They're powerful, useful, and well-documented, so there are many different resources available to help you get the most out of them.
They're also generally overkill for just harvesting blog post titles. If you need a complete SEO audit of a site, great! You can perform that with something like Greenflare very easily. I still would recommend you point it at your own site and not someone else's unless you're being paid to do so, though.
It's still a clunky solution. Fortunately, there's something better.
The Best Option: Topicfinder!
That's right; the site you're on here!
I made Topicfinder as a tool for myself to solve this exact problem. I wanted to do competitive research to figure out what the competition looked like and what the blogs were about, primarily for my clients, who come from a huge range of different industries and occupations.
I had one goal: scrape titles from blogs, strip them of the cruft, and come up with a usable list of ideas. Some I could take as-is for generic topics, some I could adapt, and some I keep in my back pocket for general-use formats. It's very handy to have.
So, for me, this was option 1. It was a custom platform I coded up. But when I realized other people could get just as much use out of it as I could, I figured, why not turn it into something I could make accessible as a product?
Topicfinder is the fruit of those efforts. It's a lot prettier and easier to use than the tool I had made for myself. It's more streamlined and faster, too, with more resources behind it. You don't have to worry about Cloudflare blocking it. You don't have to worry about rate limiting or proxy server rotations. While it does use a credits system, one single credit gets you 100 titles pulled from a blog of your choice, and you get at least 100 of them per day.
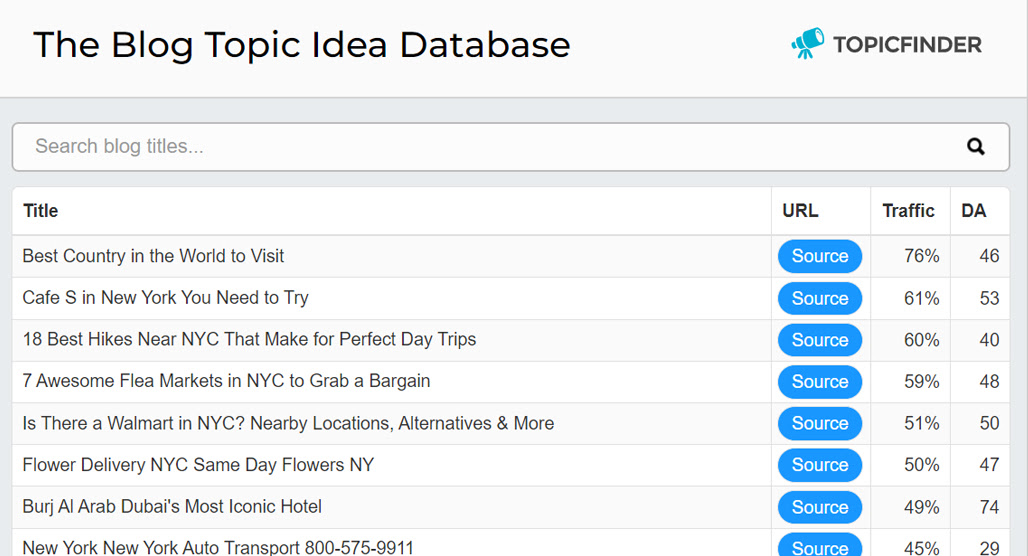
I don't just scrape page titles for you, either. Topicfinder is smart enough to only go for blog posts and can trim out all of that added cruft like brand names, anything after a pipe (|) or dash (--), and anything else you don't need.
- Here's what it looks like in action.
- Here's an idea of what it can generate for you.
- And here's a link to the free trial if you want to try it yourself.
I made Topicfinder as the exact solution to this specific need. You aren't getting all of the SEO auditing you would with Greenflare or Screaming Frog, sure. You aren't getting the hassle of managing API credits or coding up a custom platform and evading Cloudflare's detection, either. All in all, it's a great way to get the data quickly and easily, so you have it when you need to plan your marketing efforts.
Related Posts



Leave a Comment


Fine-tuned for competitive creators
Topicfinder is designed by a content marketing agency that writes hundreds of longform articles every month and competes at the highest level. It’s tailor-built for competitive content teams, marketers, and businesses.
Get Started